簡介
這裡整理了開發人員的過往經驗, 匯集其開發過程的筆記並經過簡單整理後撰寫的
網羅了程式語言、應用開發、學術等各個領域的資料, 也包含開發人員常用的技巧分享等
整理過程中, 若發現有缺少的資料, 也會盡量找到相關資訊並且補上
流程圖大部分使用 https://www.diagrams.net 繪製
形式上, 會透過以下方式分類:
# Topic
- Overview
- section 1
- section 2
- section 3
- section 4
- section 4.1
- section 4.2
Overview 的內容, 會補充 Topic 可能會用到的工具、參考資料的統整之類的
Section 的內容, 則依照整理者細分主題的各個小單元進行補充
寫作習慣
參考資料
HTML 基礎語法 - https://developer.mozilla.org/zh-TW/docs/Web/HTML
CSS 基礎語法 - https://developer.mozilla.org/zh-TW/docs/Web/CSS
JavaScript 基礎語法 - https://developer.mozilla.org/zh-TW/docs/Learn/JavaScript/First_steps
React 官方文件 - https://zh-hant.reactjs.org/
WebAPI - https://developer.mozilla.org/zh-TW/docs/Web/API
Restful API - https://docs.microsoft.com/zh-tw/azure/architecture/best-practices/api-design
TypeScript - https://www.typescriptlang.org/community
web.dev - https://web.dev/learn/
撰寫工具
本文件使用 MdBook 撰寫
Git
Git 是一個免費和開源的分佈式版本控制系統, 旨在以速度和效率處理從小型到大型項目的所有內容
Install
請直接到 git 的官方網站 進行安裝, 如果是 Windows 的使用者, 建議可以順便安裝 git-bash 作為終端機使用
他模擬了 Linux 的 Bash, 若是同時在 Linux 與 Windows 上都有開發需求的人員, 可以統一使用 Bash 的指令
此外, 也會同時安裝 Git GUI, 這工具可以讓使用者使用圖形化介面查看 Git Repos 的資訊
不過官方也有推薦其他的工具, 比較知名的像是 SourceTree 或是 Github Desktop
SourceTree

Github Desktop

各位可以在 Git 的客戶端介紹 頁面, 看到統整的各個軟體, 找到自己喜歡的使用
筆者大部分是使用 cli 以及 Visual Studio Code 內建的 git 功能 + 額外的 plugins, 因此沒有安裝 GUI 軟體
Quick Start
官方有非常詳細的 Git 指南 供開發人員參考
倘若你從未使用過Git, 可以參考下方的資訊快速上手
| Command | 作用 |
|---|---|
| git clone <url> | 複製一個 Repos 到本地端 |
| git init | 在本地端初始化一個Git Repos |
| git add <pattern> | 追蹤符合<pattern> 的檔案 |
| git status | 列出目前的 Repos 狀態 |
| git diff | 除了列出Repos狀態外, 額外列出改變的檔案內容 |
| git commit | 提交一個變更 |
| git log | 檢視 Repos 的歷史紀錄 |
| git remote | 設定遠端的相關資訊 |
| git push <remote> <branch> | 推送變更到指定 Repos 的分支上 |
| git pull | 獲取並合併遠端 Repos 的分支 |
這裡快速列出了常用的指令, 這裡列出幾個情境:
1. 獲取遠端的Repos
舉例來說, 如果我想要下載 https://github.com/torvalds/linux 這個儲存庫
若我在 ~/workdir 這個目錄下執行指令:
git clone https://github.com/torvalds/linux
那麼便會建立 ~/workdir/hellogitworld 這個資料夾, 裡面有 linux repo 的相關資訊
也可以在 clone 時, 指定資料夾:
git clone https://github.com/torvalds/linux linux-kernel
那麼便會建立 ~/workdir/linux-kernel 這個資料夾, 裡面有 linux repo 的相關資訊
如果是要下載大型的 Repos 時, 可以加上 --depth=1 參數, 就只會抓取最新版本的紀錄
2. 建立一個遠端的Repos
比如說我現在於本地端沒有 Repos, 我想要建立一個 Repos 並上傳至託管網站(例如 github)
git init
這會初始化目前的資料夾, 作為git 的 Repos。此時可以使用 git status, 會列出尚未追蹤的檔案
這時候就可以使用 git add 追蹤檔案和 git commit 提交此次變更
git add *.cc # 追蹤所有附檔名為 ,\.cc 的檔案
git add <name> # 追蹤 <name> 這個檔案, 如果 <name> 是資料夾, 追蹤資料夾下的所有文件
git commit -m "message" # 提交變更, 並註記資訊 message
git commit -a # 提交COMMIT_MESSAGE檔案
git add 是使用 GLOB 的格式來匹配檔案的, 不過第一次提交通常使用 .gitignore 設定要忽略的檔案, 再使用 git add . 追蹤整個專案
最後透過 push 指令, 提交首次的變更到遠端上, 因為第一次要指定特定的遠端位置, 所以須透過 -u 參數來設定
git push -u <remote> <branch>
與遠端協同工作
在與提交資料到git server之前, 必須處理好有關的 git 與 ssh 資訊
如果是 windows 用戶這裡建議使用 powershell 或是 git-bash
首先到使用者的家目錄(通常是 c:/Users/<username>), 然後建立 .ssh 資料夾
在該資料夾下, 使用指令 ssh-keygen
mkdir -p ~/.ssh # 建立 .ssh 資料夾, 如果已經存在可以忽略
cd ~/.ssh # 建立 .ssh 資料夾, 如果已經存在可以忽略
ssh-keygen # 建立 RSA Key-pair, 可使用 -t 選擇其他加密法
接下來會問你生成的金鑰名稱以及 Passphrase, Passphrase 可以忽略沒關係
金鑰名稱若沒有設定, 預設會是 id_rsa, 或是加密法的名稱, 例如使用 -t ed25519 預設名稱就會是 id_25519
若使用預設名稱, 應該會生成 id_rsa 跟 id_rsa.pub 兩個檔案
接下來, 假設你是 github 用戶, 請登入後點擊右上方的圖像, 找到 Settings 這個分類, 並找到 Access / SSH and GPG Keys 這個選項後, 點擊右上方的 New SSH Key, 會看到該畫面:
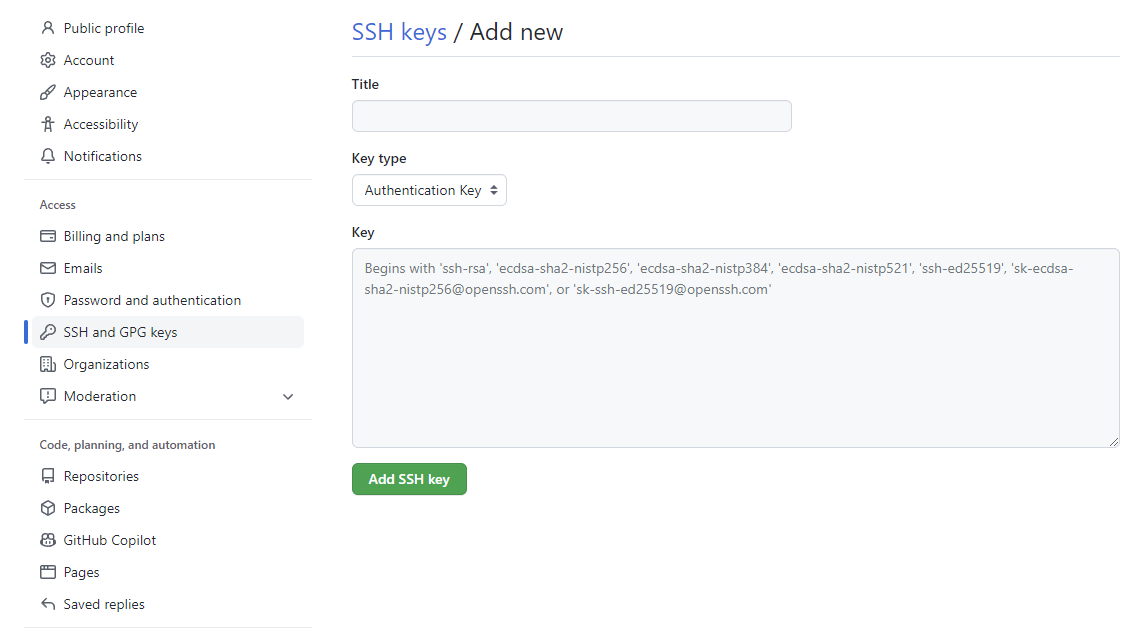
Title 可以輸入足夠你辨識的資訊即可;而Key 則輸入 id_rsa.pub 的內容
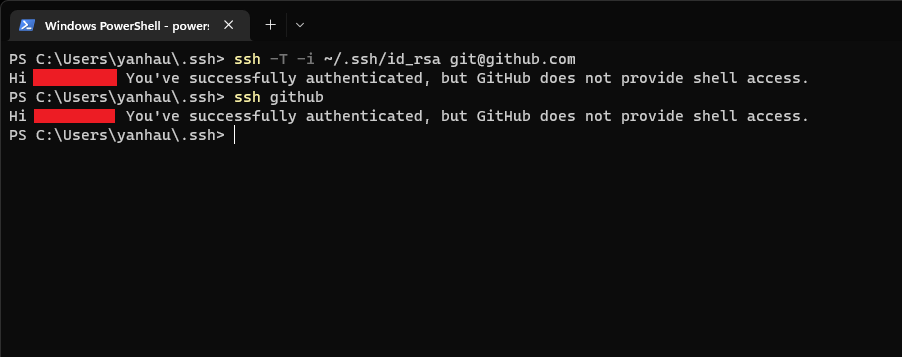
完成後儲存, 回到終端機, 嘗試對 github 進行 SSH 登入:
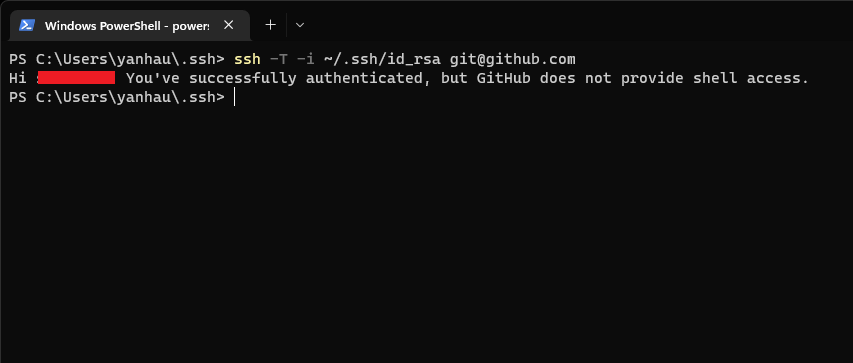
-i 參數是設定使用的金鑰 -T 則是告知 github, 不需要分配一個終端機
通常 ssh-keygen 產生的金鑰對都會是 <name> 跟 <name>.pub, 分別是私鑰跟公鑰
公鑰提供給 github 或是 gitlab, 私鑰則用來登入。上圖中的紅框處, 應該要是你的github 名稱
ssh config
如果每次都要這樣處理, 會顯得過於麻煩, 因此可以使用 ssh config 設定登入資訊
在 ~/.ssh 目錄下, 建立一個 Config 檔案, 內容輸入:
Host github
HostName github.com
User git
IdentityFile ~/.ssh/id_rsa
Host 是供你辨識的連線名稱 HostName 用來設定伺服器的位置, 可以是網域或是 ip User 是登入的用戶名稱 IdentityFile 則是私鑰的檔案位置
當設定好 .ssh/config 的資訊, 可以嘗試用 Host 連線, 比方說
ssh github
就會發現可以順利連線, 當然 ssh config 可以設定多組資訊, 比方說:
Host github-alex
HostName github.com
User git
IdentityFile ~/.ssh/alex
Host github-benson
HostName github.com
User git
IdentityFile ~/.ssh/benson
Host gitlab-howard
HostName github.com
User git
IdentityFile ~/.ssh/howard
因為本質是用來進行 ssh 登入的, 因此也可以設定給 Linux 主機做登入資訊, 但是這裡不細談
以上的做法, 適用於 windows/linux, 範例中使用 github, 但是 gitlab也有同樣的機制
與遠端交互
最後一個階段, 要來設定 git remote, 不管在 github 還是 gitlab 上, 你的Repos 通常會在 /<username>/<repo-name> 這個路徑, 例如前面提到的https://github.com/torvalds/linux, username就是torvalds, repo-name則是linux
因此, 若你是Repos的創建者, 請先到 github 建立一個repos, 假設你的名字叫做foo而且repo-name是bar, 那你的repos URL 應該是 https://github.com/foo/bar
此時要設定 git remote 的資訊, 請使用
# git remote add <name> <url>
git remote add origin https://github.com/foo/bar
通常 name 會使用 origin, url 則是你的 repo 位置, 但是這裡考慮到未來push/pull 會需要驗證, 所以建議把 url 改成 ssh config 的資訊, 例如
git remote add origin github:foo/bar
其實在 github, clone 時會給你選 https , ssh , github-cli 三種方式, ssh 給你的URL會是 [email protected]:<username>/<repo>.git 只需要把 ssh config 的 host 替換 [email protected] 即可, 這在 gitlab 或是其他託管網站應該都是一樣的
最後使用
git push -u origin master
把東西推上 origin(= github:foo/bar) 的 master 分支上
開發流程
因為這個文件是給 git 新手看的文件, 因此 merge / branch 等遠端合作的注意事項, 建議直接看 Gitlab Flow 或是 git flow、github flow 等資料
Git Flow 的邏輯是
- 有個主要的分支, 比方說
master或是release放置目前運行或是發行出去的版本 - 同時會有個開發分支
develop, 主要的工作會在該分支上進行 - 有新的需求時, 從
developfork 新的feature-<name>分支- 登入/登出/會員功能 fork
feature-authorization分支 - UI優化 fork
feature-UI分支 - 照片上傳功能 fork
feature-photo-upload分支
- 登入/登出/會員功能 fork
- 完成功能後, merge 回去
develop分支 - 當有個BUG需要緊急處理的時候, 從
master分支 forkbugfix- 一定要從
master分支 fork, 因為develop分支可能還會有些開發中、不穩定的功能 - 修復bug完成後, 合併到
master跟develop分支(若沒有合併回develop, 下個版本進入master時, 該bug又會出現)
- 一定要從
- 可能會建立
release分支, 通常是上線前的最後測試
而 gitlab flow 與 github flow , 都是在此情況下進行簡化/修改, 重點都是著重在區分開發中 和 穩定 功能的分支, 依照團隊情況使用即可
Commit Message
如果專案只有你自己一個人, 那麼 Commit Message 只要寫你看得懂的格式就好
但是當團隊進行合作時, 建議要討論好 commit message 的格式, 通常都會拆成
<Header> - 摘要本次變更的內容
(option)<Body> - 詳細說明本次變更的內容
(option)<Footer> - 額外的註記
每個段落都會用 \n 隔開, 一個良好的範例是:
簡單來說, Header作為摘要不要過長; Body則可以描述這次提交你做了什麼;Footer是個可選的區塊, 未必要填寫, 如果有使用 Redmine 之類的專案管理軟體, 可以註記 issue 編號
筆者認為, commit message 未必要寫得非常專業, 以 Google 的範例來說, 他們的 Header 會分成 chore, deprecate, feat, fix, release 五種
分別去對應
- chore - 一些自動化/例行的任務之類的
- deprecate - 註記一些功能是應該被淘汰的
- feat - 新增一個新的功能
- fix - 修復一些錯誤或bug
- release - 一些與版本有關的註記
當然, 也有更複雜的區分, 例如:
- feat: 新的功能
- fix: 修復錯誤
- docs: 程式碼文件相關的修改(CHANGELOG、README、或是其他文件等)
- style: 不影響程式的邏輯, 調整原始碼(code format, 空格數量、加上遺漏的分號等)
- refactor: 不添加新功能或是修復bug的情況, 重構程式碼(可能是拆分成更小的模組、又更優美的寫法...等)
- perf: 效能改善, 或者是添加一些追蹤效能的程式碼
- test: 新增測試文件
- ci: 對於CI相關設定的調整
Header 也可能加上修改的scope, 可能是功能/或是某個模組之類的
feat($browser): add onUrlChange event (popstate/hashchange/polling)
New $browser event:
- forward popstate event if available
- forward hashchange event if popstate not available
- do polling when neither popstate nor hashchange available
Breaks $browser.onHashChange, which was removed (use onUrlChange instead)
fix($compile): add unit tests for IE9
Older IEs serialize html uppercased, but IE9 does not... Would be better to expect case insensitive, unfortunately jasmine does not allow to user regexps for throw expectations.
Closes #392 Breaks foo.bar api, foo.baz should be used instead
這樣在 git log --oneline 時, 可以清楚看到如:
2d0e1ea feat($browser): add onUrlChange event (popstate/hashchange/polling)
a2cc062 fix($compile): add unit tests for IE9
3f1cbb7 feat(directive): add directives disabled/checked/multiple/readonly/selected
e717ffc style($location): add couple of missing semi colons
b62050d docs(guide): update fixed docs from Google Docs
ea303d0 feat($compile): simplify isolate scope bindings
7f5cdfc initial commit
而當透過 git log 查看紀錄的時候, 更快速檢閱相關的變更
反過來說, 如果哪天需要追查特定的bug, 或是想理解軟體開發脈絡的時候, 看到如下的紀錄:
2d0e1ea update
a2cc062 commit
3f1cbb7 fix
e717ffc commit
b62050d update
ea303d0 update
7f5cdfc initial commit
看起來很荒謬對吧? 但是這樣寫的人其實很多, 這才是最可怕的事情
Body 跟 Footer 先不論, 甚至有沒有寫先不管, 至少在 Header 的部分, 要好好摘要你做了哪些事情
因此希望各位, 至少先從"寫好 commit" 這件事情開始學
JavaScript Core 概觀
在討論 JavaScript 的語法之前, 首先快速的理解一下這個程式語言他能做到什麼事情, 以及他在現今擔任的角色
JavaScript 是一種腳本, 也能稱它為程式語言, 可以讓你在網頁中實現出複雜的功能
當網頁不只呈現靜態的內容, 另外提供了像是:內容即時更新、地圖交動、繪製 2D/3D 圖形, 影片播放控制……等, 你就可以大膽地認為 JavaScript 已經參與其中
以上是 MDN 對 JavaScript 的介紹。大家通常的印象, JavaScript就是用在與網頁互動的應用上, 和 HTML、CSS 三者構築成網頁的基石
本章節不著重在網頁(或者說, 前端)應用的開發, 而是專注在 JavaScript 上, 得益於 Google V8 引擎的優異性能, 早在數年前 JavaScript 便可獨立於瀏覽器運作;
更進階一些的情境, 也適用於嵌入式系統。
換而言之, JavaScript 可以在不同的環境下運行, 這個部份最後再來回顧, 但是這裡要介紹的是 "核心的 JavaScript", 也就是與執行環境無關的部分。
Runtime environment
本章節所有的範例, 可以透過 Node.js或是 Browser DevTools 運作, Node.js 的架構在章節4會提及;
簡單的說:Node.js 是一個執行環境, 採用Google V8引擎, 套用非阻塞與事件驅動的模型
在 Node.js 以外, 在主流的瀏覽器, 按下 F12 或是 Ctrl + Shift + I 的組合鍵, 也可以呼叫出 DevTools, 同樣也包含了 JavaScript 的執行環境
References
本節內容主要依照
O'REILLY JavaScript Cookbook
O'REILLY JavaScript: The Definitive Guide
以及 MDN 中的 JavaScript Basic
做為參考依據, 萃取並簡化內容, 盡可能快速讓初學者理解 JavaScript 的核心概念, 章節末則整理常用的函式
語法速覽
本小節快速說明 JavaScript 的語法, 若曾有程式開發經驗, 只要快速略過就好
變數宣告
var i = "str"; // 宣告一個變數
let j = 0; // 宣告一個變數, After ES6
const k = 100; // 宣告一個常數, After ES6
/*
* 多行註解
*/
// 單行註解
在早期(ES6以前), 通常使用 var 關鍵字來宣告變數, ES6以後的版本則可以使用 let 或 const 宣告變數, 不過 var 以及 let 的行為並不相同, 最好都使用 let來宣告, 這個問題保留在此處說明1
絕大多數, 請優先使用 const 進行宣告, 其次才是使用 let 宣告
若要明確聲明一個全域變數, 可以用globalThis.locale = "zh-TW" 的方式來宣告, 以宣告成員的方式指定一個變數, 這可以很好的釐清變數所在的scope
型別字面值
字面值的意思是, 直接提供給 JavaScript 變數的值, 且不使用建構式初始化, 舉例來說, 陣列可以使用以下兩種方式宣告:
let users = ['Alex', 'Bob', 'Claire']; // literals
let users = new Array('Alex', 'Bob', 'Claire'); // constructor
在多數的情況下, 最好使用字面值(literals) 來初始化內建型別
- Boolean:
true,false - Numerical:
- (十進制) decimal:
0,100,-123 - (八進制) octal:
015,021,-0o73 - (十六進制) hex:
0x15,0x153,-0xf1A7(a~f 不區分大小寫) - (二進制) binary:
0b11,0b0011,-0b11
- (十進制) decimal:
- Floating:
.123,-.01,0.123,-0.1234,1e-34,1E+12 - String:
'str, asd \n\r',"123 45 a1bd", `template string` - RegExp:
/[a-z]*/ - Array:
[0,1,2,3,4,5] - Object:
{ a: 30, b: "str", c: true }
比較特殊的部分是Template String, 他是由兩個 ` 符號構成的字串, 可以在其中使用${ expr }嵌入表達式:
const name = "Alex";
const age = 18;
const info = `${name} is ${age} year-old Man`
// 輸出 "Alex is 18 year-old Man"
定義類別
class Rect {
constructor(x1, y1, x2, y2) {
/* 成員在建構式中宣告 */
this.x1 = x1;
this.y1 = y1;
this.x2 = x2;
this.y2 = y2;
}
/* 宣告方法 */
getArea() {
return Math.abs((this.x2 - this.x1) * (this.y2 - this.y1));
}
}
class Rect {
constructor(x1, y1, x2, y2) {
/* 成員在建構式中宣告 */
this.x1 = x1;
this.y1 = y1;
this.x2 = x2;
this.y2 = y2;
}
/* 宣告方法 */
getArea() {
return Math.abs((this.x2 - this.x1) * (this.y2 - this.y1));
}
}
/* 繼承 */
class Square extends Rect {
constructor(x1, y1, x2, y2) {
super(x1, y1, x2, y2); // 呼叫父類別的建構式
}
}
陣列
let numberArr1 = [1,2,3,4,5];
let numberArr2 = new Array([1,2,3,4,5]); // 這是一個二維陣列
let charArr = Array.from("abcdef"); // 若引數是擁有迭代器介面的型別, 則可以通過 Array.from 創造一個淺層陣列
// result: charArr = ['a','b','c','d','e','f'];
function range( start, stop, step = 1) {
return Array.from({ length: 1 + (stop - start) / step }, (_, i) => start + (i*step))
}
range(0, 5) // [0,1,2,3,4,5]
分支結構
let condtion = 1;
// if-else
if ( condition ) {
} else {
}
// switch-case
switch( condition ) {
case 0: /* do something */ break;
case 1: /* do something */ break;
case 2: /* do something */ break;
default: break;
}
迴圈結構
let i = 0, j = 0, k = 0;
while( i < 100 ) {
/* do something */
if ( j == 50 ) continue;
if ( k == 60 ) break;
++i;
}
for(let i = 0 ; i < 100 ; ++i) {
/* dosomething */
}
迭代器
let obj = {
a: 1,
b: 2,
c: 3,
d: 4,
key: 5,
index: 6,
};
/* for ... in 存取物件上的 enumable 屬性 */
for(let key in obj) {} // --- s1
for(const key in obj) {
console.log(key) // 依序印出 'a' 'b' 'c' 'd' 'key' 'index'
}
/* for ... of 存取擁有迭代器介面之物件的內容 */
let arr = [1,2,3,4,5,6];
for(let value of arr) {}
for(const value of arr) { // --- s2
console.log(value); // 依序印出 1 2 3 4 5 6
}
雖然可以使用 let 或是 const 來宣告 for...in 與 for...of 存取的屬性 / 值 (如 s1, s2 標示的部分)
但建議都使用 const 來存取, 因為存取到變數通常是拷貝的值, 而不是副本(C++的 references &)
除非是[{}, {}, {}] 此種內容為物件型別的陣列, 才可能通過 value.property = value 進行修改, 但是也不會修改到 value 本身的參考
因此使用 const 處理迭代器是較好的選擇
錯誤處理
try {
throw new Error("Error");
} catch (error) {
console.error(error);
}
/* catch 的 error 可以省略 */
try {
throw new Error("Error");
} catch {
console.error("something wrong");
}
以上就是 JavaScript 的常用語法, 大部分都是 C-style 的樣子
let 與 var 宣告變數
在 JavaScript 的宣告中, 有一個特殊規則 "提升"(hoist)
舉個例子來說:
function sayHello(name) {
console.log(`${name} say: Hello!`);
}
sayHello("Alex");
以及
sayHello("Alex");
function sayHello(name) {
console.log(`${name} say: Hello!`);
}
兩個例子, 程式都可以順利運作;對於 C 語言的開發人員, 可能不會覺得很特殊
畢竟本來就可以先宣告函式原型, 在宣告實作
但是以下的例子, 就顯得更特殊一點:
num = 7;
num = num2 + 1;
var num;
console.log(num);

這個例子中, "看起來"好像跟預期的結果一樣, Runtime的時候告訴, 並沒有宣告 num2 這個變數, 但是修改一樣範例程式碼:
num = 7;
num = num2 + 1;
var num, num2; //多宣告 num2
console.log(num);
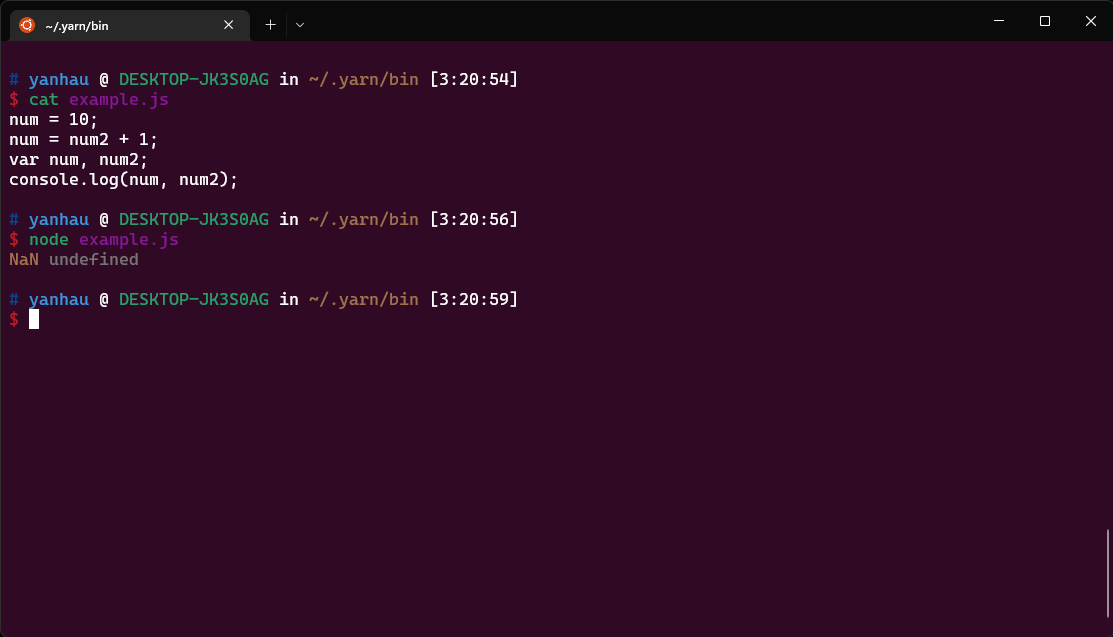
令人驚訝的事情出現了, 此時並沒有擲出 ReferenceError, 程式碼的行為就如同:
var num, num2;
num = 7;
num = num2 + 1;
console.log(num);
因為就像是把宣告給"提升"到區域的最前面, 所以該行為才被如此稱呼
對於使用 var 來宣告的變數, 所有的宣告都被提至函數的最前面, 請注意, 僅有宣告, 初始化的行為還是在原本的位置:
var x = 1;
console.log(x , y) // 1 undefined
var y = 2;
換句話說, 該語法可以解釋成:
var x;
var y;
x = 1;
console.log(x, y);
y = 2;
正如 MDN 宣稱的
這個行為算是該語言的歷史包袱, 而在ES6之後, 則出現了 let 與 const 關鍵字
有何不同
最大的差異在於, var 的宣告基於 函數(function), let 與 const 的宣告基於 區塊(block)
舉出兩個例子:
// Example 1
function foo() {
{
/* scope 1 */
var a = 10;
}
{
/* scope 2 */
var b = a + 10;
}
console.log( b );
}
foo() // output: 20
vs
// Example 2
function foo() {
{
/* scope 1 */
let a = 10;
}
{
/* scope 2 */
let b = a + 10; // ReferenceError:a is not defined
}
console.log( b );
}
foo() // ReferenceError:a
兩個行為非常明顯, 例子2無須多做解釋, 其行為與一般程式撰寫的邏輯相同
而例子一, 因為var 基於函數的範圍, 因此可以理解成:
function foo() {
var a;
var b;
{
/* scope 1 */
a = 10;
}
{
/* scope 2 */
b = a + 10;
}
console.log( b );
}
foo() // output: 20
因此只要在函數底下的任何區塊, 使用 var 宣告, 該變數在整個函數內都可以看見, 一個簡單的處理方式是使用 IIFE(Immediately Invoked Function Expression)
function foo() {
(function(){
/* scope 1 */
var a = 10;
})();
(function(){
/* scope 2 */
var b = a + 10; // ReferenceError:a is not defined
})();
console.log( b );
}
foo() // ReferenceError:a
透過包裹一層立即調用的函數, 把變數給隔離起來
既然問題可以解決, 那麼為什麼還需要let 跟 const 呢?
就是為了讓 JavaScript 的行為, 更符合現代語言, 且 let 還導入了暫時性死區(TDZ) 的概念, 防止一個變數在使用前, 被其他函數或變數引用
i = j + 10; // 可以運行
var i ,j;
x = y + 10; // ReferenceError
let x, y;
此外, var 宣告很容易沒有注意到, 就錯誤的使用, 例如在HTML的 <script></script> 撰寫如下的程式碼:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
</body>
<script>
/* some javascript code */
for(var i = 0; i < n; ++i) { // <-- for 是一個 block, 不是 function, 隱含的宣告了全域變數 i
/* do something */
}
let j = i + 1 // j 的值相當於 i 離開 for迴圈時的值 +1
</script>
</html>
如上圖所示, 或者是在 function 宣告時, 底下只要不小心使用到 var 宣告, 該變數馬上就會變成該函數內可見的變數, 另一個原因是, 在瀏覽器的行為中, Global區塊使用var 宣告的變數, 會被掛載到 window 物件底下:
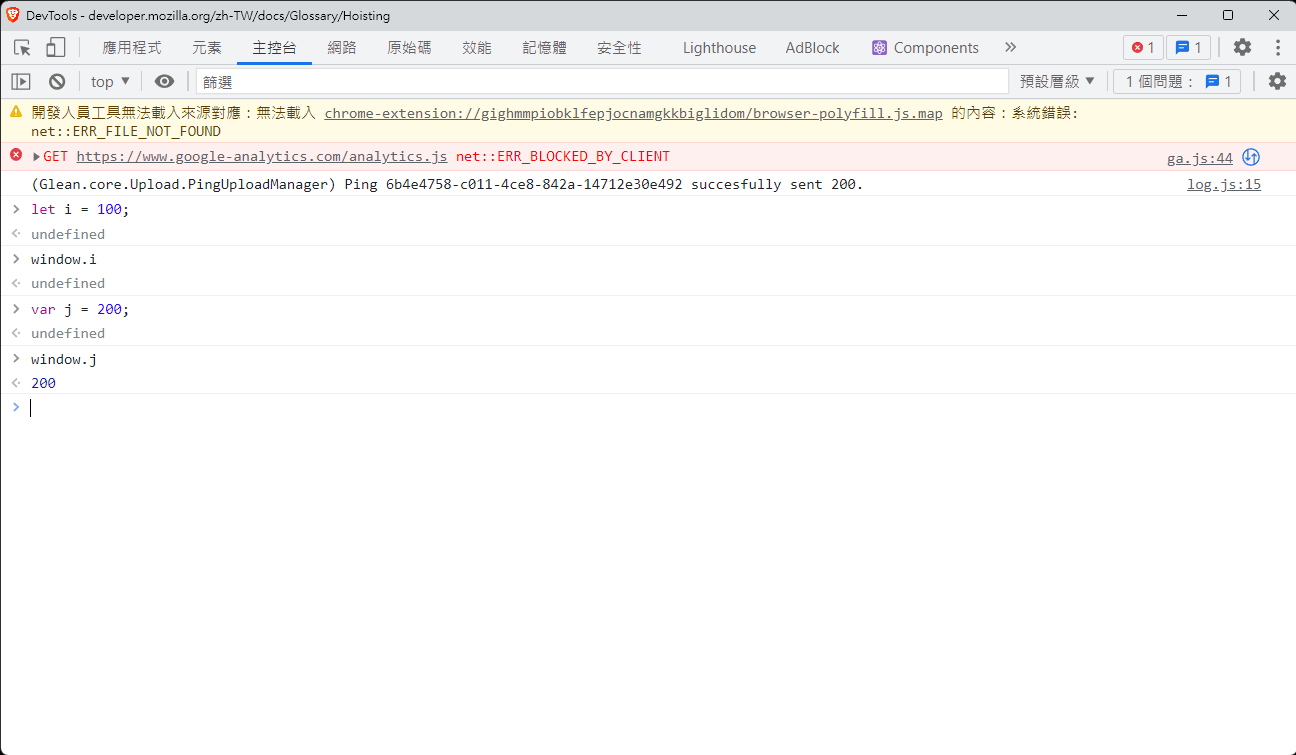
因此, 在現代的 JavaScript 撰寫中, 請盡可能避免 var 的使用
型別系統
在該章節中, 來釐清 JavaScript 中的型別系統
在 JavaScript 中, 可以分成基礎型別(或稱原始型別)與複合型別
基礎的 7 種型別分別為
- Boolean(true, false)
- Number
- String
- Null
- Undefined
- Bigint
- Symbol
複合型別包含了
- Function
- Object
快速理解 JavaScript 中的型別系統
基礎型別 (Primitive Data Type)
對於 Boolean、Number、String 這幾個型別可以用很簡單的方式說明
Boolean 即為 false、true 兩個字面值
Number 則是相當於C++的double值(-(2^53-1) ~ 2^53 - 1)的數值。除了這個範圍的數值中, 還包含了Infinity、-Infinity、NaN 三個數值。Infinity、-Infinity 相當於正負無限
NaN 則是代表 Not a Number, 通常會出現在不合法的運算, 例如
let result = "string" - 100; // NaN
let result2 = "test" * 100 // NaN
let value1 = 100 / 0 // Infinity
let value2 = Math.log(0) // -Infinity
typeof result === "number" // true
請注意, "不合法的運算"是指, 使用非"number"型別的運算子進行運算, 並非是指 100 / 0 這種運算錯誤
此外, NaN 意思雖然是 Not a Number , 但是型別是 number 若要正確檢測 NaN 的型別, 請使用 isNaN() 函式
String 則是指使用 ''、""、以及``所包覆起來的文字, 'string' 與 "string" 還有 `string` 三者是同義的, 而第三種以(``)則是樣板字串(Template String), 可以嵌入變數
let name = "username"
let str = `Hello, ${name}`
console.log(str) // "Hello, username"
// 等價以下語法:
let str_ = 'Hello, ' + name;
// 允許巢狀嵌入
let condtion = false;
let val1 = "a1234567";
let val2 = "b24681357";
let output = `condtion output: ${condtion ? `val1=${val1}` : `val2=${val2}`}`;
console.log(output) // "condtion output: val2=b24681357"
Bigint 則是大數型別, 在數字後加上n, 轉型為大數型別。當數字超過一定的範圍, 會用字串型別進行處理, 而Bigint提供了很基礎的運算:
let val1 = 2 ** 2000 // value out of number range: "Infinity"
let val2 = 2n ** 2000n /*
114813069527425452423283320117768198402231770208869520047764273682576626139237031385
665948631650626991844596463898746277344711896086305533142593135616665318539129989145
312280000688779148240044871428926990063486244781615463646388363947317026040466353970
904996558162398808944629605623311649536164221970332681344168908984458505602379484807
914058900934776500429002716706625830522008132236281291761267883317206598995396418127
021779858404042159853183251540889433902091920554957783589672039160081957216630582755
380425583726015528348786419432054508915275783882625175435528800822842770817965453762
184851149029376 */
Symbol 是個稍微複雜的型別, 通常用來建立一個獨特的 Key 值, 並作為物件中的成員值 更具體的細節請參考 Symbol
而關鍵字 typeof 則是列出運算式的型別, 其回傳值必定是以下幾個字串:
- "bigint"
- "boolean"
- "function"
- "number"
- "object"
- "string"
- "symbol"
- "undefined"
其中要注意的是, typeof null的回傳結果是 object, typeof NaN的回傳結果是 number
複合型別
Object 與 Function 是複合型別, 嚴格來說, 僅有 Object 型別才對
先從 Object 開始提起:
在 JavaScript 中, Object "模擬"成 C++ 的類別, 但是又有點不太相同
在JavaScript中, 物件的實現方法稱為 "原型鏈" 或是繼承鏈, 這裡用 C++ 的 Virtual Function 來說明:
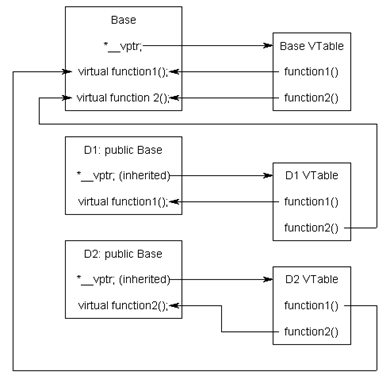
倘若 D1 與 D2 皆繼承了 Base Class, 當調用 D1.function1 或是 D2.function2, 會先嘗試尋找類別本身的定義, 倘若本身無定義的話;會嘗試調用 Base 上的定義
這與 JavaScript 物件的行為十分類似, 在JavaScript 存在著所謂原型鏈的定義。
先看看早期的JavaScript如何定義物件:
/* Define Class, JavaScript 5 */
function User(name, job) {
// 這可以判斷 User 是被作為constructor調用, 還是通過 function invoke
if(!(this instanceof User)) {
throw new Error("User should use `new` to create Object");
}
this.name = name;
this.job = job;
}
User.prototype.intro = function(){
console.log("My name is " + this.name + " , is a " + this.job);
}
var user = new User('Alex', 'student');
user.intro(); // output "My name is Alex , is a student"
user.intro = function() {
console.log("[" + this.name + ", " + this.job + "]");
}
user.intro() // output "[Alex, student]"
請注意 prototype 這個屬性, 可以把該屬性當成 Virtual Member Table, 當調用 user.intro 時,
會依序檢查 user.intro --> user.prototype.intro --> Object.prototype
對於所有 JavaScript 物件, 都是繼承自 Object.prototype
在以前沒有 class 關鍵字時, 是使用 function 作為函式定義, 所以需要使用 this instanceof <FunctionName> 來檢查是調用 User() 還是 new User
關於更多類別的說明, 會在下個章節中說明
深拷貝與淺拷貝
對於物件的比較, 不能用一般的方式進行比較, 這是因為物件的行為比較接近C++中的指標 or 參考
舉例來說:
let arr0 = new Array() // 補充一下, 可以使用 new 來建立陣列
let arr1 = [1,2,3,4]; // 若使用 [] 和 {} 來建構陣列或物件, 這種作法稱為字面值(Literal Value)宣告
let arr2 = [1,2,3,4];
let arr3 = arr2
arr1 === arr2 // false
arr3 === arr2 // true
在該例子中, arr1 與 arr2 有著一樣的成員, 比較結果卻是 false
反之, arr2和arr3 的比較結果是 true。起初會有些疑惑, 但是用等效的C++程式碼說明:
int* arr1 = new int(4);
int* arr2 = new int(4);
int* arr3 = arr1;
arr1 === arr2 // false(因為 address 不同)
arr3 === arr2 // true(因為 address 相同)
這可以說明JavaScript中物件的作法, 有些類似C++中的參考, 比方說
function append(arr, value) {
arr.push(value);
}
let x = [];
append(x, 100);
console.log(x) // [100]
let y = x;
append(y, 200);
console.log(x) // [100, 200]
當第一次調用 append 時, 會把 x 的位址傳入 append;因此外部的 x 被修改了
接下來把 y 指向 x, 然後調用append(y, 200), 再次檢查 x 的值, 會發現 x 值再次被修改了
對於第二次 append, 可以看做 append 內部的 arr 指向 y , y 又指向 x, 因此才會被修改
淺拷貝的意思是:不同物件的成員, 擁有相同的參考, 即為淺拷貝。舉例來說
let Parent = {
arr: [0, 1, 2, 3, 4]
};
let ChildA = {
arr: Parent.arr
};
let ChildB = {
arr: Parent.arr
};
// ChildA.arr === ChildB.arr
在這種情況下, 因為已經有參考的概念了, 所以會注意到 arr: Parent.arr 把同一個物件指定給 ChildA 跟 ChildB 了
方法同理:
function a(message) { console.log(message); }
function c(message) { console.log(message); }
let b = a;
a == b // true
a == c // false
若你對 JavaScript 有點概念, 可能知道 Object 可以使用 Parent.arr 或是 Parent["arr"] 的方式使用成員, 因此你有可能誤用以下的做法:
function clone(source, target) {
for(const [key, value] of Object.entries(source) ) {
target[key] = value;
}
}
let ChildC = {};
let ChildD = {};
clone(Parent, ChildC);
clone(Parent, ChildD);
ChildC === ChildD // false
ChildC.arr === ChildD.arr // true
一個大原則是, 如果是 {}, [], function(){} 這三種型別的變數, 在 operator= 或是 參數傳遞的時候, 都是傳入自身的參考
而 this 則是相對特殊的參考, 這個會在下一章節提到
深拷貝
深拷貝的定義相對單純, 可以解釋為不同物件的成員, 都擁有不同的參考
以上面的定義, 若要複製 array, 有幾種方法:
let arr = [0,1,2,3,4];
// sol1?
function clone(source) {
let temp = [];
for(const value of source)
temp.push(value);
return temp;
}
let arr1 = clone(arr);
// sol2?
let arr2 = [...arr];
// sol3?
let arr3 = arr.map(e => e);
//sol4:
let arr4 = JSON.parse(JSON.stringify(arr));
// arr1 ~ arr4 的值皆為 [0,1,2,3,4], 且都不等於 arr
但是請注意, 倘若陣列中的值是物件, 比方說[{}, {}, {}, {}], 那麼 arr1 ~ arr4 雖然互不相等
但是 arr1[0]、arr2[0]、arr[0] 都會等於 arr[0], 因為他們內部都是指向 arr[0]
而 arr4 則是完全複製, 也就是說進行arr4[0].x = 100 這種修改, 是不會影響到arr[0]的
因此, 僅有 sol4 才算是深拷貝, 因為他是先把物件進行 JSON 的序列化, 在反序列化回來
但這種作法無法複製function(JSON.stringify 不會轉譯function), 也不會複製undefined
通常深拷貝的使用次數不多, 且都有Library可以處理, 因此只要有概念即可
型別間的比較
在前面幾個章節, 會發現交錯使用 == 和 ===, 有些人會說 === 指的是嚴格比較, 該說法有點道理, 但是實際上更單純
先從 JavaScript 的運算子說明, 每個運算子都會定義兩邊的運算元型別, 而JavaScript有個轉換的優先順序:
/* '+' 運算子可以用在 string + string 或是 number + number */
let a = 'str' + 'ing' //string + string
let b = 1 + 2 // number + number
let c = '200' + 100 // string 的優先度高於 number, 先把 100 轉為 '100', 然後相加字串
c // '200100'
/* '-' 運算子僅能用在 number + number */
let d = '1000' - 100 // - 僅接受兩個 number, 嘗試把 '1000'轉為 1000, 然後相減
d // 900
let e = '100a' - 100 // '100a' 無法轉換為 number, 該計算結果為 NaN
那麼回到 == 和 ===, == 的語意是比較時, 允許型別轉換;=== 的語意則是 比較時, 不允許型別轉換
大致上來說, 轉換的順序可以看成 string > number > boolean, 當運算元是不同型別的時候, 會向上轉換一階:
console.log(true == 1) // true
console.log(true == 'true') // false
/* 分析一下 true == 'true' 這個例子 */
console.log(true == 1) // 代表 Number(true) 會轉成 1
console.log('1' == 1) // 代表 String(1) 會轉成 '1'
console.log(true == '1') // true, 左側進行 String(Number(true)) 得到 '1'
但凡事都存在例外, 物件可以定義 toString 以及 toJSON, 來決定被轉換成 string 和 JSON 的方法
Object 的轉換都會直接隱式調用 obj.toString() 方法
let obj = {};
obj == 10000 // false, 因為 obj 會轉換成 '[object Object]', 此時變成 compare(string, number)
//於是 10000 會進行 String(10000) 得到 '10000', 而 '[object Object]' 不相等於 '10000'
let objA = {};
objA == '[object Object]' // true
// 手動定義 toString 方法
objA.toString = function(){
return 10000
}
objA == 10000 // true
而 === 和 !== 就是告知JS引擎, 比較時不允許隱式轉換型別
比較時, 都使用 === 來進行比較是最好的, 如果要針對型別轉換後比較, 最好是顯式的調用轉型運算
如: "100" === (100).toString() 把兩者都轉換成 string
或是 parseInt("100") === (100).toString() 把兩者都轉換成 number
深入理解
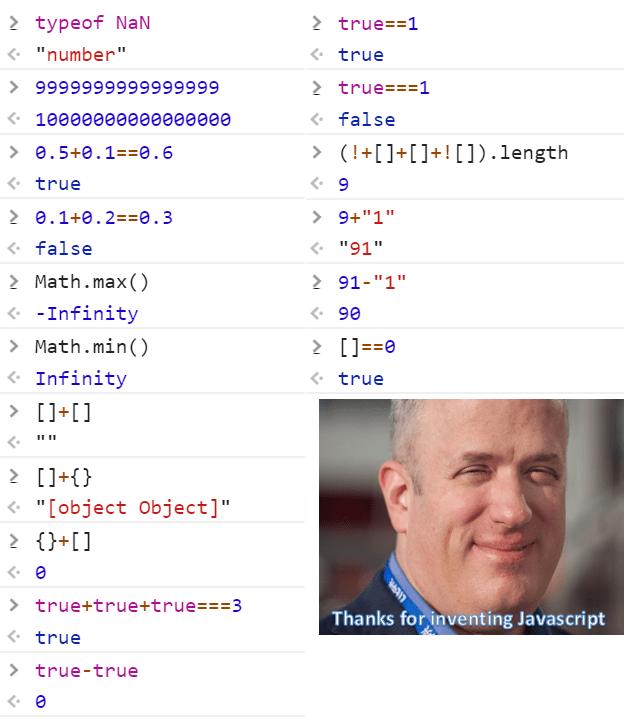
由左至右, 由上至下來說明這個梗圖:
typeof NaN
typeof NaN 前有說明, NaN 定義於 IEEE 754, 表示無效操作(不等同於算數溢位), 但是沒有特別定義 NaN 是否為 number
在JS中, 使用 isNaN 來檢測 NaN 值
9999999999999999
9999999999999999 == 10000000000000000 是浮點數的誤差
0.5+0.1 , 0.1+0.2
僅出現在 0.1 + 0.2 的時候, 浮點數會出現誤差
而 0.5 + 0.1 並不會, 這也是 IEEE 754 的錯誤, 高精度比較法可以用
function equal(a, b) {
let value = Math.abs(a - b);
return value < 1e-15;
}
equal(0.1+0.2 , 0.3) // true
其中 1e-15 是可以自行定義的門檻值, 核心概念為"當計算結果小於一個誤差值, 視為相同"
Math.max , Math.min
Math.max 的簽章是 Math.max(n1, n2, n3, ...) 會回傳參數中的最大數值
他內部的實作類似:
Math.max = function(...args) {
let currentValue = -Infinity;
for(const value of args) {
if(value > currentValue)
currentValue = value;
}
return currentValue;
}
照上圖的 Math.max() 實作, 沒有傳入參數的話, 會導致 for-loop 不進行疊代, 所以直接回傳currentValue, 也就是 -Infinity
Math.min的狀況類似, 只是 if 判斷改成 value < currentValue
[ ]+[ ], [ ]+{ }, { }+[ ]
[] + [], 在陣列中, 轉換為 string 實際上是調用了 join 這個方法, 因此
let arr = [1,2,3,4,5,6,7];
arr == arr.join(); // true
arr.join() // '1,2,3,4,5,6,7'
arr == arr.join(' '); // false
arr.join(' ') //1 2 3 4 5 6 7
Array.join(token = ",") 的作法是先把陣列的所有元素轉換為 string 型別, 再透過 token 連接起來
[] + {} 則是如同前面說的, 會先把 [] 轉換成 '', 然後把 {} 轉換成 '[object Object]'再把 '' + '[object Object]' 字串合併得到 '[object Object]'
{} + [] 為0比較特殊, 因為 {} 不可進行估算, 所以實際上會看成 {} (+[]), 而+[] 會轉成 0, 然後進行 {} 0 得出0
這看起來是這個奇怪的結果? 首先要知道JS引擎首次估算是用直譯的, 所以具體的過程是:
// {} 0 改寫成
{
/* empty scope */
}
0
換句話說, {} + []前面的{} 不是物件, 而是當成scope的宣告;接下來後面接一個數值, 因此得出 0
證據就是, ()內不允許定義scope, 僅允許 expr, 倘若改成 ({}) + [] 就會視作兩個值進行+運算, 所以會轉換成 '[object Object]' + '', ({}) + [] 就會等同 [] + {}
true+true+true, true-true, true==1, true ===1
拆解成
true會轉為 Number 1==會進行型別轉換;===不會轉換- boolean 會先嘗試轉換為
number, 然後是string
(!+[]+[]+![]).length
(!+[]+[]+![]).length
先拆解成
!(+[])-+[]會變成+'', 然後轉為 0, !0 會轉為true[]- 轉換成''![]-[]轉換成true, 然後運算!true得到false
三個值相加得到 'truefalse', 該字串長度為 9
9+"1", 91-"1"
請看上面章節型別間的比較
17
[] == 0 因為 Number([]) 轉換成 0, 0 == 0 得到 true
物件與類別
上個章節中, 提到了原型鏈的概念
繼續深入類別之前, 先來看看ES 5之前的類別是如何實現的:
/* Class Example */
function Rect(w,h) {
if(!(this instanceof Rect)) // No
throw new Error('is constructor');
this.w = w;
this.h = h;
}
Rect.prototype.add = function (r) {
if(!(r instanceof Rect))
throw new TypeError('Only allow Rect-type');
this.w += r.w;
this.h += r.h;
}
Rect.prototype.print = function () {
console.log(this.w + ', ' + this.h);
}
let r1 = new Rect(1,1);
let r2 = new Rect(2,2);
r1.add(r2);
r1.print(); // '3, 3'
這裡定義 Rect 型別, 並宣告了 add 與 print 方法的實作。
當宣告了一個物件時, 便可以同時定義他的prototype
已知, 當調用 function 的順序(例如 Rect.add)時, 會依序查找Rect.add Rect.prototype.add Object.prototype.add
/* Class-like Example */
function Rect(w,h) {
return {
w: w,
h: h,
add: function(r) {
this.w += r.w;
this.h += r.h;
},
print: function() {
console.log(this.w + ', '+ this.h);
}
}
}
let r1 = Rect(1,1);
let r2 = Rect(2,2);
r1.add(r2);
r1.print()
這個行為"看起來"會跟使用 new Rect 一樣, 但是有個非常嚴重的問題, 就是r1.add !== r2.add
這個問題的嚴重性在於, 假定定義了像是MyClass 這種類別, 並且有個方法 myFunction, 當建立了 1000 個實例
myFunction 也會被建立1000次, 這對於記憶體的處理是非常不健康的
邏輯上, 成員變數應該保持在自己的scope, 而方法(例如 MyClass.myFunction) 是一個獨立的 function, 由所有的MyClass共用該 function 位址
僅需要傳入自己的參考, MyClass 便會假設 this 是自己傳進來的參考;
再次使用C++來舉例, C++的class實作隱含了this參數, 比方說
class Point {
public:
Point(int x, int y): x_(x), y_(y) {}
void add(Point p) {
this.x_ += p.x_;
this.y_ += p.y_;
}
private:
int x_;
int y_;
}
實際上, add 的簽章會包含一個隱含的參數 this
void Point::add(Point* this, Point p) {
this.x_ += p.x_;
this.y_ += p.y_;
}
如果要驗證這一點, 通過 std::bind 這個函式可以更好的觀察到
#include <iostream>
#include <functional>
class Point {
public:
Point(int x, int y): x_(x), y_(y) {}
void add(Point& p) {
this->x_ += p.x_;
this->y_ += p.y_;
}
int x_;
int y_;
};
int main() {
Point p1(1,1);
Point p2(3,3);
Point POINT(10,10);
auto fn = std::bind(&Point::add, &POINT, std::placeholders::_1);
fn(p1);
std::cout << POINT.x_ << ", " << POINT.y_ << "\n";
//11, 11
fn(p2);
std::cout << POINT.x_ << ", " << POINT.y_ << "\n";
//14, 14
}
逐步拆解以上的過程:
class Point宣告了addfunction, 允許兩個Point進行加法- 把
fn通過std::bind繫結了Point::add這個函式, 並且把this的 Context 繫結在POINT上 - 透過
std::placeholders, 繫結fn的第一個引數與Point::add的第一個參數 - 調用
fn(p1)時, 相當於調用了POINT.add(p1) - 調用
fn(p2)時, 相當於調用了POINT.add(p2)
以筆者的理解來說明:
在Class的實現上, 可以拆解為 屬性 以及 方法
屬性是由實例自行維護的數據區塊
方法則是所有的實例共享同樣的函式宣告與實作
所有的方法雖然共用相同的function 區段, 但是因為隱含了 *this, 所以不同實例調用方法才會呈現不同的結果
可以參考 MSDN C++ 上的 __thiscall
部分程式語言, 如 Rustlang, 則要求在成員的方法實作, 顯式宣告第一個參數為 &self
在 JavaScript 上, 早期的 Class 實作要求使用 function 來宣告, 在 Rect 該例中
早期開發人員通過 if(!(this instanceof Rect)) 判斷 Rect 是通過建構式被調用, 還是通過一般函式被調用
因為一般函式與建構式的調用, this 的數值是不相同的(在下個章節進行討論)
function 的定義統一被移到 <Class Name>.prototype 這個區段, 而屬性則由實例自行維護
因此前兩個例子中:
Class Example所有的Rect實例, 會共享Rect.prototype.add與Rect.prototype.print的實現Class-like Example所有的Rect實例, 不會共享Rect.prototype.add與Rect.prototype.print的實現, 相當於add與print的實現每次在Rect()調用時, 都被重新宣告/實現一次。
在例子2中, 使用的實例越多, 記憶體的使用則越劇烈
ES6 底下的類別
幸好在 ES6 (ECMA 2016)以後的標準, 提供了 class 與 extends 關鍵字, 上方的 Rect 可寫為:
class Rect {
constructor(w, h) {
this.w = w;
this.h = h;
}
add(r) {
this.w += r.w;
this.h += r.h;
}
print() {
console.log(this.w + ', ' + this.h);
}
}
let r1 = new Rect(1,1);
let r2 = new Rect(2,2);
r1.add(r2);
r1.print(); // '3, 3'
倘若多定義了 Square 正方形類別, 只需要透過 extends 關鍵字即可
class Square extends Rect {
constructor(w) {
super(w, w);
}
getArea() {
return this.w * this.h;
}
}
let s1 = new Square(10);
s1.getArea(); // 100
super 關鍵字會依照不同context, 決定super的數值。在此處中, 是調用 Parent Class 的建構式
在以前, 需要手動處理 prototype 的指向來模擬繼承敘述:
// Rect - 父類別
function Rect(w,h) {
if(!(this instanceof Rect))
throw new Error('is constructor');
this.w = w;
this.h = h;
}
// 父類別的方法
Rect.prototype.add = function (r) {
if(!(r instanceof Rect)) // 可以通過 "instanceof" 判斷傳入的原型
throw new TypeError('Only allow Rect-type');
this.w += r.w;
this.h += r.h;
}
Rect.prototype.print = function () {
console.log(this.w + ', ' + this.h);
}
// Square - 子類別
function Square() {
Rect.call(this); // call super constructor.
}
// 子類別擴展(extends)父類別
Square.prototype = Object.create(Rect.prototype);
Square.prototype.constructor = Square;
var rect = new Square();
console.log('Is rect an instance of Square?', rect instanceof Square); // true
console.log('Is rect an instance of Rect?', rect instanceof Rect); // true
rect.move(1, 1); // Outputs, 'Shape moved.'
倘若加上了 static 關鍵字, 其行為如同 C++的靜態方法:
class Square extends Rect {
static internal = -1;
constructor(w) {
super(w, w);
}
getArea() {
return this.w * this.h;
}
}
let s1 = new Square(10);
s1.getArea(); // 100
Square.internal // -1
// ES 5 以前:
function Square(w) {
if(!(this instanceof Square))
throw new Error('');
}
Square.prototype.getArea = function(){ /* impl */ }
Square.internal = -1;
此外, 類別可以使用 new Square 或是 new Square() 的方式初始化(假設建構式不需要參數), 他們的差異是運算子優先順序
因為成員存取算運子.的優先度比較高, 所以使用
new Square.getArea 會導致錯誤, 因為 Square 不存在 getArea 這個靜態方法, 但是使用
new Square().getArea 則不會出錯, 因為他實際上調用了 (new Square).getArea
This 變數
在該章節之前, 要先提及嚴格模式 strict mode
提供開發者語法嚴格、語法受限的模式 (strict mode)
會影響語法的使用但沒支援受限模式的瀏覽器一樣可以跑, 只是行為有很大的可能會跟你想的不一樣
所以別太依賴受限模式, 除非你做過功能性測試
另外這個模式可以混用在普通模式裡, 你可以利用這個特性慢慢把舊的程式碼轉變成完全嚴謹和低變化性的狀態
嚴格模式通常會直接在腳本的第一行撰寫 use "strict"; 啟動, 嚴格模式可以參考MDN的說明
- 透過拋出錯誤的方式消除一些安靜的錯誤(意指不再靜默地忽略某些錯誤)
- 修正會阻礙 JavaScript 引擎進行最佳化的錯誤: 相同的程式碼在嚴格模式有時候能運行得比非嚴格模式來的快
- 禁止使用一些有可能被未來版本 ECMAScript 定義的語法
在開發WEB應用時, 基本上是一定會加上的, 因為他會使JavaScript的行為更接近現代化的程式語言
關於 This
對於一般的function, 查找this的範圍會從調用者(caller)往上查找:
"use strict";
let obj = {
prop: 300,
fn: function() {
return this.prop;
}
}
function outerFn() {
return this.prop;
}
obj.fn() // 300;
obj.fn2 = outerFn;
obj.fn2() // 300, 因為此時 outerFn 繫結於 obj 的成員位址
outerFn() // Error, this 並沒有 prop 這個成員
this的判斷, 是先依照是不是作為某個物件的屬性或方法被調用
在上述的例子中, 因為 outerFn 是直接以一個 function 被調用, 而不是某個物件底下的方法, 所以 this 的值為 undefined
但經過 obj.fn2 指向 outerFn, 此時 obj.fn2 同樣是調用 outerFn, 但是是以 obj的成員被調用
因此 this 的值相當於 obj
舉例來說:
function fn() {
return this.prop;
}
let obj = {
prop: 100,
foo: fn,
sub: {
prop: 200,
foo: fn
}
}
obj.foo(); // 100, 因為此時是以 "obj" 的成員被調用, this = obj.sub
obj.sub.foo(); // 200, 因為此時是以 "obj.sub" 的成員被調用, this = obj.sub
// 修改obj.sub為
obj.sub = {
foo: fn
}
obj.sub.foo() // undefined, 此時同樣以 "obj.sub" 的成員被調用, 但是 obj.sub 已經不存在 prop 屬性了
obj.sub.__proto__.prop = 300;
obj.sub.foo() // 300, 最直接的引用是 obj.sub, 該物件沒有prop成員, 但是原型鏈(__proto__)存在prop成員
閉包與 arrow function
箭頭函數(arrow function), 也被叫作 "Lambda" 表達式, 其表示法如下
// ex.1
const sum = (a, b) => {
return a + b;
};
// ex.2 當 `=>` 後接的是 expression 時, 可以當作回傳值
const sum = (a, b) => a + b // 行為同 ex.1
// ex.3
const sayHello = (name) => `Hello, ${name}`
// ex.4
const sayHello = name => `Hello, ${name}` // 只有一個參數時, 可以省略()
// ex.5
const returnObj = ( user ) => ({
name: user.first + ' ' + user.last,
age: user.age,
})
// 倘若使用 user => {}, 此時的 {} 會被視作 block statement, 使用 ({}) 則視為 object expression
this對於一般函數來說, this 有幾種可能值:
- 作為 new 建構子來說, this指向物件本身
- 對於strict mode下直接調用函式, 函式中的 this 是
undefined - 作為物件的方法呼叫時, 參考至物件上
而 arrow function () => {} 的行為, 是基於詞法域(lexical), 而非語法語境(context)
function a() {} 以及 let a = () => {} 絕對是不同的東西
在一些前端框架, 如 Reactv15 之前或是 Vue 開發的時候, 官方會強調, 何時一定要使用 function, 而不能用 arrow function 代替
function Person() {
this.age = 1;
setInterval(function growUp(){
this.age++; // 錯誤, 因為 setInterval 的調用不是由 Person 的instance 執行, 是由瀏覽器進行排程
// 通常為 undefined, 非嚴格模式下為 window
});
}
// solution
function Person() {
this.age = 1;
const self = this;
setInterval(function growUp(){
self.age++; // 正確運作, 先用 self 把 this 的位址保存下來, 並透過閉包傳遞
});
}
// solution 2
function Person() {
this.age = 1;
setInterval(() => {
this.age++ // 正確, 因為arrow function 的 this 是基於詞法域的
console.log(this.age)
})
}
要快速釐清 arrow function 與 一般 function 的使用時機時:
使用 function() {} 宣告的時機:
- 在物件中, 方法要參照物件本身
- 在類別中, 宣告成員函式的情景
- 使用到 Generator
function*的情況 - 使用 arguments 的情況
除此之外, 都可以直接使用() => {} Arrow Function 的形式來宣告函式
但原則上來說, 盡可能使用展開運算替代arguments, 因此動態參數的情況, 也可以使用 arrow function
"use strict";
let id = "ID-Global"
let obj = {
id: "ID-Object",
fn1: function () {
console.log(this.id, "in" , this);
},
fn2: () => {
console.log(this.id, "in", this);
},
inter: {
fn1: function () {
console.log(this.id, "in" , this);
},
fn2: () => {
console.log(this.id, "in", this);
}
}
}
obj.fn1(); // 會印出 `ID-Object` in obj 中
obj.fn2(); // 會印出 `undefined` in window 中
obj.inter.fn1(); // 會印出 `undefined` in obj.inter 中
obj.inter.fn2(); // 會印出 `undefined` in window 中
以此例來說, fn1 使用 normal function 進行宣告, 因此 this 的值參照到 obj 上;
fn2 使用 arrow function 宣告, 此處的 obj.fn2 與 obj.inter.fn2 的宣告, 因為使用 Object literal
此時的obj的定義是在 window 物件下;而 obj.fn1 與 obj.inter.fn1 分別參照宣告的物件, 所以分別是 obj 與 obj.inter
"use strict";
let outFn;
new (function() {
this.data = 30;
let fn1 = function () {
console.log("fn1: this is",this);
}
let fn2 = () => {
console.log("fn2: this is", this);
}
fn1();
fn2();
outFn = fn2;
});
outFn();
這個例子中, 揭露了 constructor 與 Object literal 的微妙差異:
此例中, fn1 並不是作為特定物件的方法調用, 因此 fn1 下的 this 為 undefined
反之, fn2 使用 arrow function, 參照的是宣告時的位置, 對應到的部分是匿名函數的內部, 因此該處的 this 會顯示 { data: 30 }
"use strict";
class Example {
constructor() {
this.data = "Example Data";
this.fn1 = function () {
console.log(this);
}
this.fn2 = () => {
console.log(this);
}
}
}
class FunctionTrigger {
constructor() {
this.data = "FunctionTrigger";
}
invoke(fn, extraMessage) {
console.group("Invoke");
console.log(extraMessage);
fn();
console.groupEnd();
}
}
const example = new Example;
const ft = new FunctionTrigger;
example.fn1(); // -- stmt1
example.fn2(); // -- stmt2
ft.invoke(example.fn1, "Try invoke example.fn1"); // -- stmt3
ft.invoke(example.fn2, "Try invoke example.fn2"); // -- stmt4
這又是另外一個例子, 當 fn1 與 fn2 作為 example 的方法調用時, 都會順利顯示 this.data = "Example Data"
但在 stmt3 中, example.fn1 作為函式傳入 ft.invoke 中在調用, 此時失去了 example 這個參照, this 的值會是 undefined
在 stmt4 中, example.fn2 即使作為函式傳入 ft.invoke 中在調用, this依然繫結在 example 上
在 JavaScript, 函式本來就有提供 bind 與 apply 兩種原型方法, 用來繫結this 當下值, 其行為如同上一章節 C++ 的 std::bind
此例中, 可以把 stmt3 改成 ft.invoke(example.fn1.bind(example), "Try invoke example.fn1"); 再次調用觀察
Function.prototype.bind 與 Function.prototype.apply 回傳結果是一個 function
example.fn1.call(example) 則是把 example 當作 this 的值直接調用
arrow function 不可使用 bind, apply, call 三種方法, 因為其上不存在
閉包、語法域與詞法域
通俗的解釋, 語法域代表的是執行期間動態決定的行為, 比方說普通函式的this、建構式的super
而詞法域代表的是封閉範圍的前後文, 如同變數的查找一樣, 舉例來說:
{ // -- block 1
let a = 100;
let b = 200;
{ // -- block 2
let c = 300;
function fn() { // -- block 2.1
console.log(a, b, c);
}
fn() // 100, 200, 300
}
{ // -- block 3
function fn() { // -- block 3.1
console.log(a, b, c);
}
fn() // 錯誤, c 不存於該 block 3.1 以及 block 3
}
}
a, b 在同一個 block, 而 c 在的block可以看到外部(block 1)
所以第一個 block 2 可以看到 a,b,c, 但是第二個僅能看到 a,b
這就是詞法域(其行為依照原始碼的樣子), 比較編譯器領域的說法是:Token 被宣告的位置
而閉包則複雜一點, 以上面的例子來說, 可以觀察出:
- block 允許巢狀
- 內部的 block 可以存取外部的 block
- 外部的 block 不可以存取內部的 block
閉包的概念, 就如透過 function, 把內部的變數帶出去外面:
function closure(initValue) {
let sum = initValue;
return function(num) {
sum += num;
return sum;
}
}
const sigmaFn = closure(0);
sigmaFn(100); // 100
sigmaFn(100); // 200
sigmaFn(100); // 300
首先定義了 closure, 僅允許傳入參數來初始化 sum
並回傳一個 function, 可以傳入數字來遞增 sum
每一次呼叫 sigma, 都會遞增 sum 的值, 這看起來似乎沒有什麼特別, 但是稍微修改一下:
function closure(initValue) {
let sum = initValue;
return {
add: function(num) {
sum += num;
return sum;
}
}
}
const calc = closure(100);
calc.add(20);
calc.add(30);
把回傳值改為物件, 並包含了sum值, 這有兩個很特殊的作用:
- 在回傳的物件中, 不需要用到
this - 無法透過 calc 直接存取 sum, 只能透過
add來存取
在早期沒有arrow function時, 閉包可以很好的處理this的context, 而第二點則至關重要:封閉了sum的直接修改, 僅允許公開的方法存取
這個行為, 就像是把 sum 定義為 private 成員, add 定義為 public 成員, 透過閉包, 模擬出物件導向的行為
現在閉包用法則是比較偏向第二點, 因為this已經有arrow function跟 class 關鍵字協助處理了
通常會使用閉包來移轉內部資料的所有權到外部
另外一個層面是, 閉包可以很好的處理早期 var 宣告的問題(請見 語法速覽), 而UMD模組載入模式, 也會看到閉包的使用
JavaScript 架構
本章節, 從非同步程式的概念開始, 假設有個程式這樣寫:
const arr = [];
arr.push(1);
arr.push(2);
arr.push(3);
arr.push(4);
console.log(arr) // [1,2,3,4]
在這個例子中, 程式碼都是由上到下執行, 因此很好預測執行結果
但如果程式碼改成以下模式:
const arr = []
let fileA = download(urlA);
let fileB = download(urlB);
let fileC = download(urlC);
while( !(fileA.done && fileB.done && fileC.done) ) {
if(fileA.done && !fileA.lock) {
arr.push(fileA.content);
fileA.writeLock();
}
if(fileB.done && !fileB.lock) {
arr.push(fileB.content);
fileB.writeLock();
}
if(fileC.done && !fileC.lock) {
arr.push(fileC.content);
fileC.writeLock();
}
}
假設download程式碼, 可以下載某個URL提供的資料, 並且分別用 done 表示下載完成, 以及 content 表示下載的內容
此例進行下載三個網站的內容, 並不斷檢測是否下載完成;如果有任何網站還未下載完成, 就不會離開迴圈
迴圈會依序檢查A、B、C的內容, 若下載完成, 把資料放入arr中, 並且上鎖防止重複寫入
答案是不確定
可以改成: arr[0] = fileA.content 這種做法來確定資料的順序, 但是當資料列表變大的情境, 要處理的細節就會越來越多
或是操作順序有時序性:需要先登入銀行、然後才能操作帳戶
當操作的步驟越來越繁瑣, 卻又需要知道式健順序, 無法確定API回傳順序時 - 在網路世界中, 程式的執行順序, 不等同於資料的取得順序
JavaScript 引擎架構
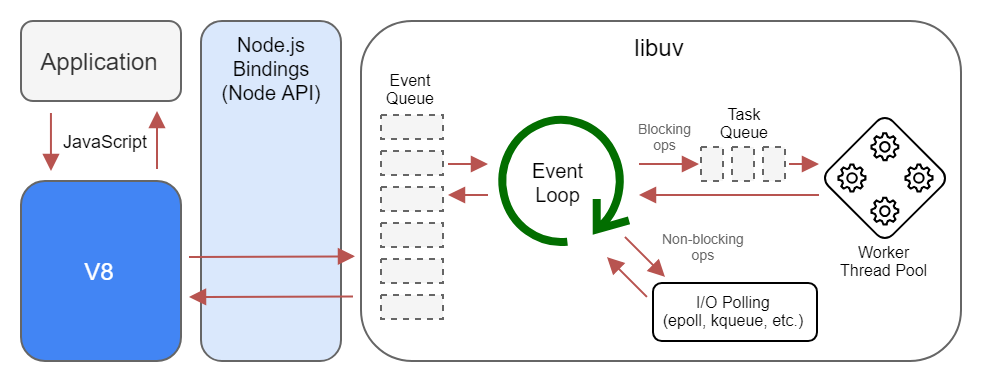
模擬一個情境:
在 C++ 中, 可能使用 cin 或是 scanf 來得到使用者的輸入, 程式碼如下:
cin >> num;
cout << "Hello, world" << endl;
cin 會嘗試取得使用者輸入, 然後輸出 "Hello, world"。但是使用者輸入之前, 畫面是不會繼續渲染的, 這在交互式的 command interface 不是問題
但是到了 GUI 卻相當嚴重, 比方說登入頁面, 在你輸入帳號、密碼之前, 畫面上其他部分都停止繪製, 這不是一個好的體驗
因此瀏覽器採用"事件驅動", 透過觀察者模式 (設計模式的一種, 不贅述), 等待用戶發出的事件, 並進行響應
<button onclick="alert('My name is Alex')">Click Me</button>
當點下按鈕後, 會push clickEvent 至事件佇列(Event Queue), 圖中的 EventLoop, 是一個無窮迴圈, 會不斷檢查Event Queue, 若裡頭有資料, 生成Task給後面的執行緒池
Task Queue 紀錄等待執行的工作, 由後方的Worker取出後執行, 完成後調用註冊的 Handler
這就是關鍵所在, 因為不知道使用者何時輸入/點擊畫面, 因此需要用某種機制來控制渲染的執行緒、網路請求執行緒、JS執行緒, 讓所有元件在正確的時間點運作
有了這個概念, 再追加補充:JavaScript有分成 main thread 與 job thread(或者說是 worker, task thread), 而所有的非同步事件會先扔至 job thread, 靜待瀏覽器調用
比方說 setTimeout(fn, ms), 接受一個function和毫秒的數值, 就會在 N 毫秒後調用該方法
setTimeout(() => console.log('test'), 1000) // 1秒後印出 'test'
可能實現的原理如下:
- 瀏覽器會初始化一個 timer, 紀錄經過的毫秒數
- 呼叫
setTimeout時, 放置一個事件在job thread - 每次 Eventloop 的週期, 當
main thread的工作清空後, 檢查job thread - 如果
job thread裡面有事件, 檢查註冊的時戳, 並比較current - reg_timestamp是否逾時 - 如果上述為真, 代表事件應該要執行了, 調用
- 回到步驟3
比方說設定了 setTimeout(fn, 1000), 當時戳相減超過 1000時 , 調用 fn
假設有個情境如下:要輸出1 ~ 5, 每一秒輸出一個數字, 程式設計如下:
setTimeout(() => console.log(1), 1000);
setTimeout(() => console.log(2), 2000);
setTimeout(() => console.log(3), 3000);
setTimeout(() => console.log(4), 4000);
setTimeout(() => console.log(5), 5000);
這時候, "好像"跟預期的一樣:
首先, 如何證明main thread結束後, 才會執行job thread的工作?
證明如下:setTimeout會把事件放入job thread, 首先設定setTimeout(fn, 0);
let arr = [];
setTimeout(() => arr.push(1), 0); // Enqueue - job thread
setTimeout(() => arr.push(2), 0); // Enqueue - job thread
setTimeout(() => arr.push(3), 0); // Enqueue - job thread
arr.push(4) // main thread
console.log(arr) // [4, 1, 2, 3]
該程式碼揭露的:因為前面三次push是放在job thread的, 因此狀況就好像:
JobThread = [fn, fn, fn];
MainThread = [fn];
必須等到 MainThread 清空後, 才會依序執行 job thread 內的工作
setTimeout 與 setInterval:
- setTimeout - 經過至少多少毫秒後, 應該調用 function
- setInterval - 每隔至少多少毫秒後, 應該調用 function
首先定義基準時間:
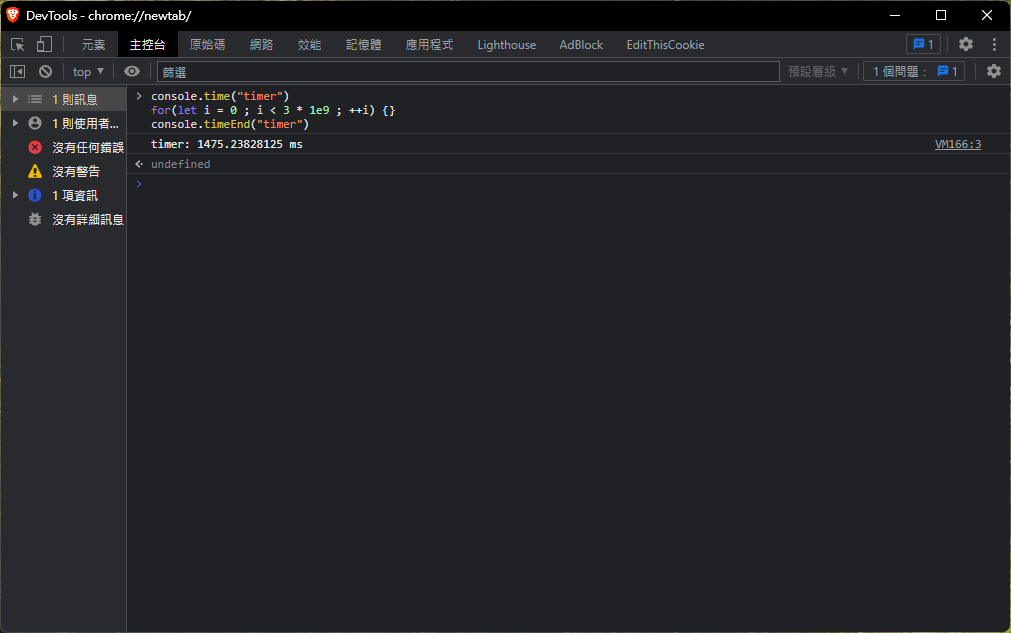
在筆者的電腦上, 執行 3 * 109次 空迴圈大約耗時 1500ms, 接下來分別推入5個事件到job thread中:
使用 performance.now用來取得分頁開啟後的累積時間, 並透過 setTimeout 放入 job thread
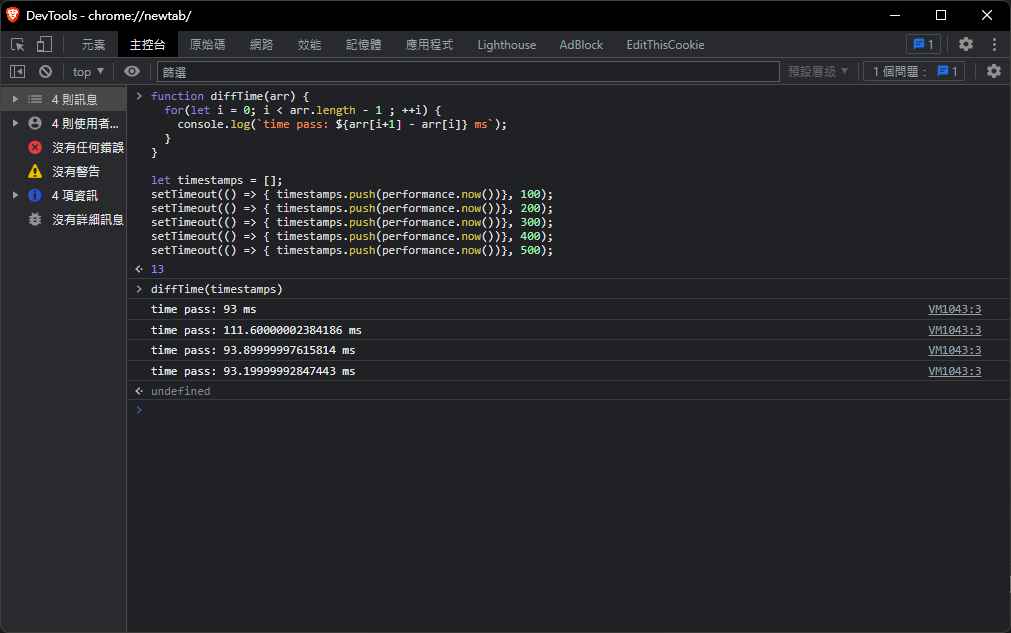
定義 diffTime:計算陣列前後項的時間差, 相當於是 setTimeout 放入時戳的間隔
首先定義五個 job, 都是放入一個時戳到timestamps[]中, 最後手動呼叫 diffTime
可以看到每一次的時間間隔大概是 90~100ms 左右
接下來設計一個實驗:
function diffTime(arr) {
for(let i = 0; i < arr.length - 1 ; ++i) {
console.log(`time pass: ${arr[i+1] - arr[i]} ms`);
}
}
// 放入5個 Task 到 job thread 中
let timestamps = [];
setTimeout(() => { timestamps.push(performance.now())}, 100);
setTimeout(() => { timestamps.push(performance.now())}, 200);
setTimeout(() => { timestamps.push(performance.now())}, 300);
setTimeout(() => { timestamps.push(performance.now())}, 400);
setTimeout(() => { timestamps.push(performance.now())}, 500);
// 使用 for-loop, 阻塞 main thread 1500ms 左右
console.time("timer")
for(let i = 0 ; i < 3 * 1e9 ; ++i) {}
console.timeEnd("timer")
// diffTime(timestamps) 最後手動呼叫, 查看每個元素被放入的時間差

這個結果的意義:
- 假定在
t0的時候執行腳本 - 分別設定事件:放入時戳到
timestamps中, 分別在t0 + (100 * i)ms的5個時間點調用push(i 表示第 i 個事件) - 程式繼續執行繼續往下, 使用
for-loop阻塞main thread1492ms - 對瀏覽器來說, 在
t0 + 1492ms的時間點後,main thread的所有任務結束 - 此時檢查
job thread中的 task, 5 個 Task 都逾時了 - 依序執行 5 個 Task
另外還有兩個單純的測試方法:
首先執行, 會看到大約每間隔一秒, 畫面會輸出一個數字
setTimeout(() => console.log(1), 1000);
setTimeout(() => console.log(2), 2000);
setTimeout(() => console.log(3), 3000);
setTimeout(() => console.log(4), 4000);
setTimeout(() => console.log(5), 5000);
接下來改成執行:
setTimeout(() => console.log(1), 1000);
setTimeout(() => console.log(2), 2000);
setTimeout(() => console.log(3), 3000);
setTimeout(() => console.log(4), 4000);
setTimeout(() => console.log(5), 5000);
window.alert('block!');
alert 會跳出一個提示框, 他會強制阻塞main thread, 等到5秒後把提示框給點掉
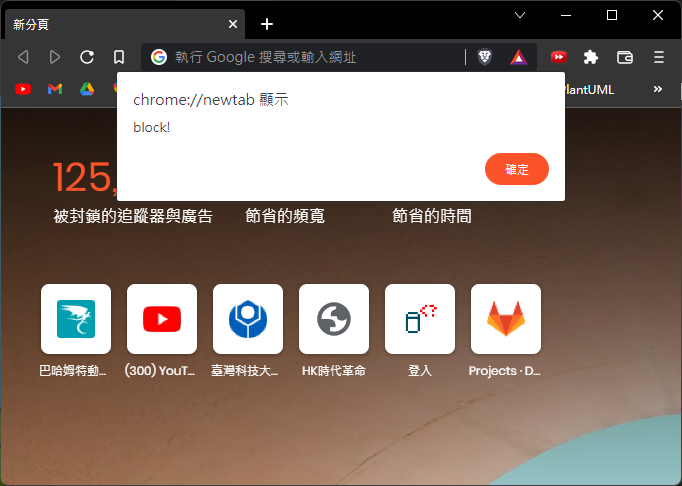
然後再看看 console.log 的輸出, 會發現1~5會同時輸出;
另一個簡單的作法:
while(true) {}
setTimeout(() => console.log(), 0); // 永不執行, 因為 main thread 被 while-loop 永遠阻塞
關於 setTimeout 或 setInterval
前述的例子中, 有點像是證明 main thread 與 job thread 的關係, 如果只是證明:setTimeout和setInterval 是至少 N 毫秒後執行
可以透過 console.time 和 console.timeEnd 兩組函數, 觀測瀏覽器回傳的時間差異
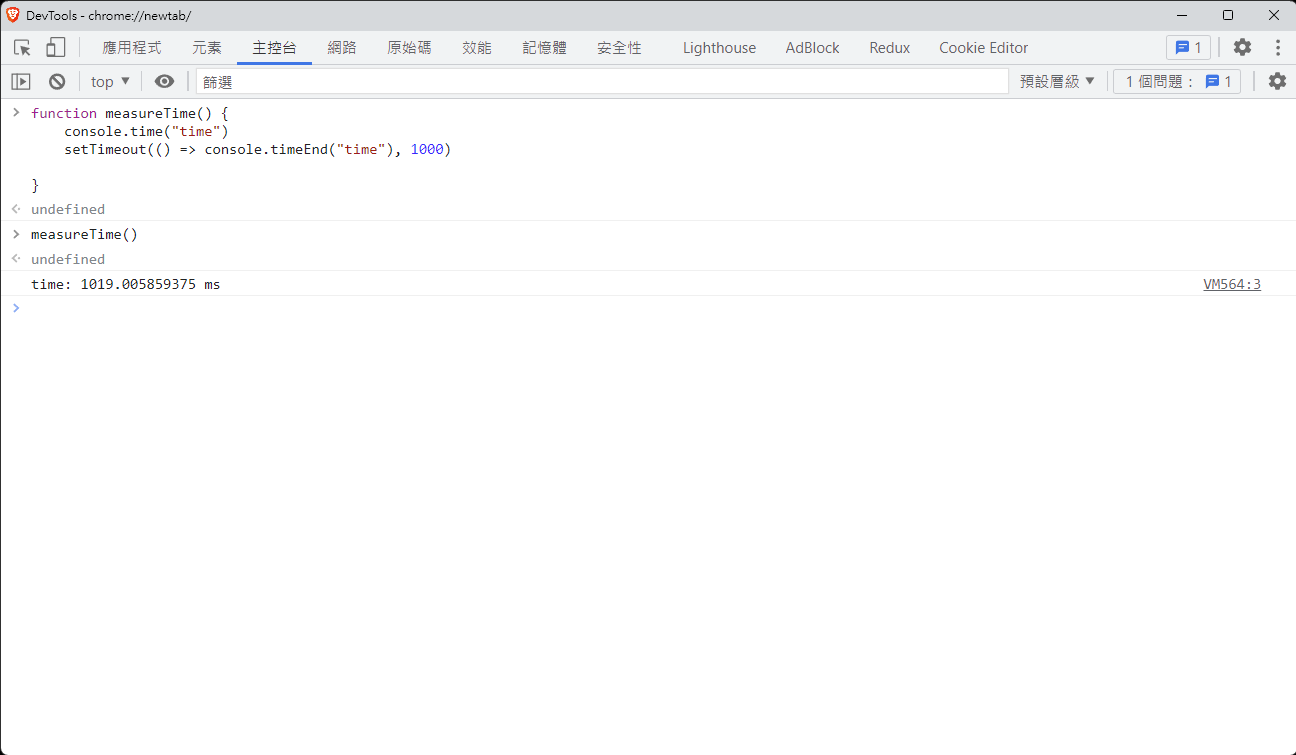
如圖所示, 計時開始與結束的時間是 1019ms, 實際上與 1000ms 還是有一點誤差
非同步程式設計
一個簡單的例子,說明一下"非同步"的情境
在假日起床後,你打算做以下幾件事情:
- 刷牙洗臉 (5分鐘)
- 洗衣服 (1小時15分鐘)
- 上廁所 (15分鐘)
- 享用早餐 (25分鐘)
一早起來先盥洗後,放下衣服去洗,上個廁所,然後享用早餐
在"同步"的情況下,會發生以下的狀況:
當盥洗後去洗衣服時,即使肚子餓了也不能用早餐;亦不能去上廁所,因為洗衣服是個阻塞事件
換句話說,當執行一個 Task,且該 Task 不可被中斷 (阻塞 Block),就可以粗略地說是同步程式
實際上的情況會更加複雜,因為會區分為:
- 同步 (Synchronize)
- 非同步 (Asynchronize)
- 阻塞 (block)
- 非阻塞 (non-block)
這裡不討論太深入,先理解第一個概念:
現實中的狀況
在生活中,也有很多非同步的情境:
- 以上個例子來說,當把衣服丟進洗衣機洗後,就會離開做其他事情了
- 煮泡麵時,通常不會倒水後,還繼續等待三分鐘都不做其他事情
- 去銀行時,先抽取號碼牌,等到輪到自己的號碼,才去櫃檯
試想一下上面的幾個情境:洗衣服時,要在洗衣機旁等待1小時;去銀行時,要在櫃台排隊直到自己到櫃檯前...
這些都是很浪費時間的情況,而以程式設計來說,通常非同步設計會用在
- I/O 發生時(非常重要)
- 某個操作耗費時間甚鉅
若 CPU 進行資料的運算需要 10µs,而等待硬碟把資料傳輸到記憶體需要 1 ms
客觀來說,耗時約為 1ms + 10µs = 1.01ms;對於CPU來說,絕大多數的時間都在等待資料傳輸
對於網頁設計來說,經典的例子是:當網頁上有圖片需要顯示時,不會等待圖片下載完成,而是會先渲染頁面的其餘部分
AJAX
政府有提供一系列的開放資料,可供查詢運輸的相關資料:MOTC API
這剛好符合即將要做的事情:透過網路從遠端取得一些資料
經由 MOTC 的 API:https://ptx.transportdata.tw/MOTC/v2/Bus/StationGroup/InterCity?$top=3&$format=JSON 可以得到以下的資料:
| 識別碼 | 站點代碼 | 站點名稱 | 經度 | 緯度 | 更新時間 |
|---|---|---|---|---|---|
| THB100-006 | 100-006 | 台電大樓 | 121.53 | 25.01 | 2022-07-31T07:15:28+08:00 |
| THB100-009 | 100-009 | 仁愛新生路口 | 121.53 | 25.03 | 2022-07-31T07:15:28+08:00 |
| THB100-013 | 100-013 | 捷運忠孝新生站 | 121.53 | 25.04 | 2022-07-31T07:15:28+08:00 |
倘若是將該表格做成網頁,內容可能會是:
<html>
<body>
<div>
<!-- 其他資料 -->
</div>
<table>
<thead>
<tr>
<th>識別碼</th>
<th>站點代碼</th>
<th>站點名稱</th>
<th>經度</th>
<th>緯度</th>
<th>更新時間</th>
</tr>
</thead>
<tbody>
<tr>
<td>THB100-006</td>
<td>100-006</td>
<td>台電大樓</td>
<td>121.53</td>
<td>25.01</td>
<td>2022-07-31T07:15:28+08:00</td>
</tr>
<tr>
<td>THB100-009</td>
<td>100-009</td>
<td>仁愛新生路口</td>
<td>121.53</td>
<td>25.03</td>
<td>2022-07-31T07:15:28+08:00</td>
</tr>
<tr>
<td>THB100-013</td>
<td>100-013</td>
<td>捷運忠孝新生站</td>
<td>121.53</td>
<td>25.04</td>
<td>2022-07-31T07:15:28+08:00</td>
</tr>
</tbody>
</table>
<div>
<!-- 其他資料 -->
</div>
</body>
</html>
這個假設的網頁,可能還包含了該表格以外的資料,使用 <!-- 其他資料 --> 替代,
假設上面的表格是會更新的(Ex. 每 30 分鐘一次),每次都需要重新要求整個頁面,是很浪費效能的
因為用戶只關心會變化的資料,比方說上面的表格
在之後,會說明什麼是RestAPI,首先知道:
早期的實現
在過去 YAHOO 帳號還很流行的時候,許多人都會去辦一組信箱:
流程如下:
- 輸入一個帳號名稱
- 輸入你的姓名、基本資料
- 送出表單
- 喔,你有可能帳號名稱跟別人重複了、或是密碼不符合格式(比方說要包含大小寫英數字)
- 重新填寫表單
在隨後幾年(2010),Google進入大家的生活,同樣的流程:
- 輸入一個帳號名稱
- 準備輸入你的姓名、基本資料
- 已經知道該帳號有沒有被註冊過了
- 繼續填寫其他項目
- 若表單有錯誤,進行修正
- 提交申請表單
這在現今很常見的技術,由 Google 開始大量使用的技術之一 - AJAX
早在 Google 使用該方法之前,早就有這項技術,叫做 Asynchronous JavaScript And XML(AJAX)
平常使用的網頁,其實大部分的畫面是固定的,僅有一小部分會變化,比方說:
- 圖書館館藏系統:只有搜尋結果的部分會改變
- 帳號註冊系統:表單都是一樣的,只是要檢查帳號、密碼合不合格
- Youtube:搜尋影片時,只有下方的影片清單會改變
諸多應用,因此提出一個概念:能不能只交換需要的部分?,或是先提交部分資料給伺服器進行處理
因為早期使用XML做為資料傳輸的格式(近幾年大部分使用JSON),所以稱為AJAX
概念如下:透過背景發起Network I/O,並等到伺服器回應後,再把資料取出來使用,實現的程式碼如下
const domain = 'ptx.transportdata.tw';
const apiPath = 'MOTC/v2/Bus/StationGroup/InterCity';
const query = '$top=3&$format=JSON';
const targetUrl = `https://${domain}/${apiPath}?${query}`;
let xhr = new XMLHttpRequest();
/* xhr.open(method, url) 以特定的HTTP方法開啟某個網址 */
xhr.open('get', targetUrl);
/* 當資料完成後,要做什麼事情 */
xhr.onload = function(e) {
console.log(xhr.responseText);
}
/* 接近等效的程式碼:
xhr.addEventListener('load', e => {
console.log(xhr.responseText);
}) */
/* 送出請求 */
xhr.send();
看到 onload 成員,當完成後,會發送一個事件,通知程式去把資料取出來
現在的主流做法
在ES 6(ECMA 2016)之後,推出了一系列的API,其中包含影響甚鉅的 Promise
而ES 7之後,則推出了 async/await ,更方便進行處理非同步的資料
Promise
Promise 的含意是:一個未來的值,且狀態決定之後,絕對不會改變
用實際的例子來說明,首先是 Promise 的函式簽章:
function executor( resolve, reject ) {
/* do something */
}
let promise = new Promise( executor );
executor 的型別是 Function,並接受兩個參數 resolve 和 reject,兩個參數都是 function
resolve:當操作成功,應該調用該方法
reject:當操作失敗,應該調用該方法
在部分程式設計書籍的說法,傳入一個Function,被傳入的Function習慣稱做 callback 或是 handler
並且稱接受/回傳一個Function的Function 為 High-order Function(高階函式)
以該例中:
function calc( callback ) {
let a = Math.random() * 100;
let b = Math.random() * 100;
return callback(a, b);
}
function add(a, b) {
return a + b;
}
function mul(a, b) {
return a * b;
}
calc(add) // return `Math.random() * 100` + `Math.random() * 100` 的值
calc(mul) // return `Math.random() * 100` * `Math.random() * 100` 的值
呼叫 calc 時,calc內部會生成兩個隨機數字 a, b,並調用 callback 參數,該參數接受一個 Function
add 和 mul 這兩個被傳入的 function,通常叫做 callback
另一個例子,滑鼠點擊事件的函數簽章:
htmlElement.addEventListener('click', e => {
console.log(e);
})
addEventListener 接收兩個參數:第一個是事件種類,常用的有 click, change, load ... 等
第二個參數則是一個 handler, 把事件物件傳給 handler, 供 handler使用
那麼回到 Promise, 可以理解成 Promise 內部會生成兩個 callback 供使用
根據調用的 callback, 決定 Promise 的狀態是成功的還是失敗的:
let promise = new Promise((resolve, reject) => {
const value = Math.random() * 1000;
if(value > 500)
resolve(value);
else
reject(value);
});
new Promise 回傳的實例, 會提供 then 或是 catch 方法,分別對應 resolve 和 reject :
promise
.then(value => console.log(value)) // 當 resolve 被調用時,進入該函式
.catch(value => console.log(value)); // 當 reject 被調用時,進入該函式
這樣理解Promise:一個未來會存在的數值, 且狀態確定後, 就不會改變了
狀態不會改變的意思是:
let promise = new Promise((resolve, reject) => {
const flag = true;
resolve(true);
reject(false); // 無效,已經呼叫了 resolve
});
promise
.then(value => console.log(value)) // print 'true';
.catch(value => console.log(value)) // 不會執行
這個就是 Promise 不變性的意思:
- 一開始處於 pending 狀態:還未調用
resolve或是reject之前, 都處於該狀態 - 當 resolve 調用後:成為 fulfilled(實現) 狀態
- 當 reject 調用後:成為 rejected(拒絕) 狀態
Promise 一旦被決定是 fulfilled 還是 rejected 後, 就不會變成其他狀態了
而 Promise 只會被決定一次狀態,意思是:
let promise = new Promise((resolve, reject) => {
const flag = true;
resolve(true); // 在該階段,Promise 成為 fulfilled 狀態
resolve(false); // 無效,Promise的狀態已經被決定了
});
而 then 和 catch 的回傳值,會成為下一個 Promise 的值:
let promise = new Promise((resolve, reject) => {
resolve(10); // 必定會成功的 Promise
});
promise
.then(value => {
console.log(value); // print 10
return value * 100
})
.then(value => {
console.log(value); // print 1000
});
且 Promise 有個特性:他可以類似串列一般,把本次的回傳值做為下一個promise的傳入
let promise = new Promise((resolve, reject) => {
const flag = Math.random() > 0.5; // Math.random() 會隨機回傳 0~1 之間的數字
if(flag) {
resolve(1,2,3,4,5) // 僅接受第一個參數
} else {
reject(10,20,30) // 僅接受第一個參數
}
});
promise
.then((a,b,c,d,e) => {
console.log(a,b,c,d,e); // print 1, undefined * 4
return 100;
})
.catch((a,b,c) => {
console.log(a,b,c); // print 10, undefined * 2
return -100;
})
.then( value => {
// 如果 flag 為 true,代表進入上一個 then,此時 value = 100
// 反之 flag 為 false,代表進入上一個 catch,此時 value = -100
console.log(value);
return 10000
})
.finally(e => {
// 可以調用 finally(),代表不論在 then 還是 catch 都要執行的事件
console.log(e) // undefined,finally不接受任何參數
})
Promise的出現,為帶來了一個重要的進展 - 可以針對非同步事件進行排序
以上個個章節的例子,要下載 fileA, fileB, fileC,且一定要依照A B C的順序
在上個章節,用arr[0]、arr[1]、arr[2]分別存入A、B、C的值,但是使用 Promise 後,可以改為:
function download(url) {
return new Promise( (resolve, reject) => {
const xhr = new XMLHttpRequest();
xhr.open('get', url);
xhr.addEventListener('load', () => {
resolve(xhr.responseText) // 下載完成後,調用 resolve
})
xhr.addEventListener('error', e => {
reject(e.message) // 若失敗,調用 reject
});
xhr.send() //送出請求
})
}
function downloadAll() {
download(siteA)
.then(data => {
console.log(data);
return download(siteB);
})
.then(data => {
console.log(data);
return download(siteC);
})
.then(data => {
console.log(data);
});
}
downloadAll() //依序呼叫 siteA、siteB、siteC 的下載內容
更深入的 Promise
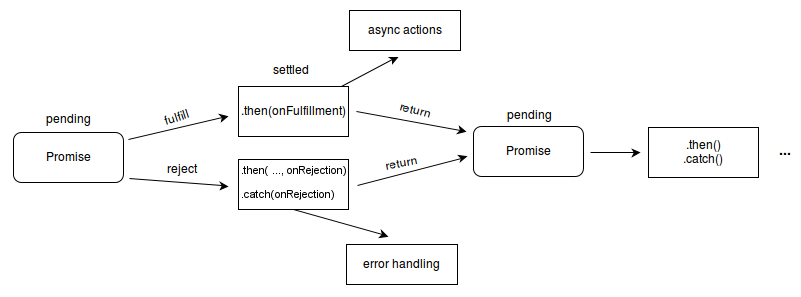
這裡引用 MDN 的 Promise 流程圖:起初在 pending 狀態,接下來根據 fulfill 或是 reject,調用 onFulfillment 或是 onRejection,此時就被稱為 settled 狀態
值得注意的地方是,可以看到其實 then() 是可以接受兩個 callback:
const invokeFn = () => Promise.reject("oops!")
/* Example 1 */
invokeFn()
.then(
() => console.log("onFulfillment"),
reason => console.log(`onReject ${reason}`)
)
.catch(
reason => console.log(`ErrorCatch, ${reason}`)
);
/* Example 2 */
invokeFn()
.then(
() => console.log("onFulfillment"),
)
.catch(
reason => console.log(`ErrorCatch, ${reason}`)
);

在舊一點的實作中, 會特意把 fulfill, reject, error 三種情況分開
Ex. 當呼叫伺服器的API時, 可能會發生:
200 OK- 伺服器收到請求並允許403 Forbidden- 伺服器收到請求並拒絕- 無回應 - 完全無回應, 可能是伺服器壞掉, 或是該站點根本不存在
對於客戶端來說, onFulfillment 對應到 status 200, onReject 對應到 status 403, 最後onCatchError 對應到伺服器無回應
- Promise.resolve(val) 回傳一個進入
fulfill狀態的 Promise 物件 - Promise.reject(val) 回傳一個進入
reject狀態的 Promise 物件
流程圖的第三階段,無論是 then 還是 catch 方法,都會會傳一個新的 Promise 物件
進階練習
這就如上方的 downloadAll 例子, 每一次的 then 都會回傳一個新的 Promise 物件, 且 Promise 只會被決定一次狀態, 因此可以提出兩種變體:
首先定義一個模擬下載 的Promise函式, 接受兩個值:val 以及 isSuccess
/* val 設定成當 Promise settled 時,應該回傳的值 */
/* isSuccess 則決定,該 Promise 的狀態是 `fulfill` 還是 `reject` */
const download = (val, isSuccess = true) => {
if(isSuccess) {
return Promise.resolve(`Fulfill: ${val}`);
} else {
return Promise.reject(`Reject: ${val}`);
}
}
download("data A")
/* stage 1 */
.then(data => {
console.log(`Savepoint 1: ${data}`);
return download("data B");
})
.catch(err => {
console.log(`Savepoint 2: ${err}`);
return download("error-data B");
})
/* stage 2 */
.then(data => {
console.log(`Savepoint 3: ${data}`);
return download("data C");
})
.catch(err => {
console.log(`Savepoint 4: ${err}`);
return download("error-data C");
})
/* stage 3 */
.then(data => {
console.log(`Savepoint 5: ${data}`);
})
.catch(err => {
console.log(`Savepoint 6: ${err}`);
})
簡單的拆解一下, 理清這個範例的執行結果:
在第一次呼叫 download 時,第二個參數 isSuccess 為 true,因此該次執行結果是 fulfill
download("data A") // fulfill
此時會經過 Savepoint 1,並印出 "Savepoint 1: Fulfill: data A"
下一行的 download("data B") 也是 fulfill,因此會略過 catch,進入到 stage 2 的 Savepoint 3,並印出 "Savepoint 3: Fulfill: data B"
同樣的,最後則會走到 stage 3 的 "Savepoint 5",並印出 "Savepoint 5: Fulfill: data C"
最終輸出:
Savepoint 1: Fulfill: data A
Savepoint 3: Fulfill: data B
Savepoint 5: Fulfill: data C
下面的例子, 把"看不到"的路徑, 先註解起來
download("data A") // <--- 目前執行的位置
/* stage 1 */
.then(data => { // <--- 最近的 then
console.log(`Savepoint 1: ${data}`);
return download("data B");
})
.catch(err => { // <--- 最近的 catch
console.log(`Savepoint 2: ${err}`);
return download("error-data B");
})
/* stage 2 */
// .then(data => {
// console.log(`Savepoint 3: ${data}`);
// return download("data C");
// })
// .catch(err => {
// console.log(`Savepoint 4: ${err}`);
// return download("error-data C");
// })
/* stage 3 */
// .then(data => {
// console.log(`Savepoint 5: ${data}`);
// })
// .catch(err => {
// console.log(`Savepoint 6: ${err}`);
// })
該次結果是成功,因此會進到 then,此時在 Savepoint 1:
// download("data A")
/* stage 1 */
.then(data => {
console.log(`Savepoint 1: ${data}`);
return download("data B"); // <--- 目前執行的位置
})
.catch(err => { // <--- 最近的 catch
console.log(`Savepoint 2: ${err}`);
return download("error-data B");
})
/* stage 2 */
.then(data => { // <--- 最近的 then
console.log(`Savepoint 3: ${data}`);
return download("data C");
})
// .catch(err => {
// console.log(`Savepoint 4: ${err}`);
// return download("error-data C");
// })
/* stage 3 */
// .then(data => {
// console.log(`Savepoint 5: ${data}`);
// })
// .catch(err => {
// console.log(`Savepoint 6: ${err}`);
// })
這次結果也是成功,因此會進到 then,此時在 Savepoint 3:
// download("data A")
/* stage 1 */
// .then(data => {
// console.log(`Savepoint 1: ${data}`);
// return download("data B");
// })
// .catch(err => {
// console.log(`Savepoint 2: ${err}`);
// return download("error-data B");
// })
/* stage 2 */
.then(data => {
console.log(`Savepoint 3: ${data}`);
return download("data C"); // <--- 目前執行的位置
})
.catch(err => {
console.log(`Savepoint 4: ${err}`);
return download("error-data C"); // <--- 最近的 catch
})
/* stage 3 */
.then(data => { // <--- 最近的 then
console.log(`Savepoint 5: ${data}`);
})
// .catch(err => {
// console.log(`Savepoint 6: ${err}`);
// })
最後的結果還是成功, 因此會進到 then,此時在 Savepoint 5:
修改範例, 比方說在 stage 1 的 then 扔出一個 Error:
download("data A")
/* stage 1 */
.then(data => {
console.log(`Savepoint 1: ${data}`);
throw "Something wrong" // <------- 加入該行
return download("data B");
})
.catch(err => {
console.log(`Savepoint 2: ${err}`);
return download("error-data B");
})
/* stage 2 */
.then(data => {
console.log(`Savepoint 3: ${data}`);
return download("data C");
})
.catch(err => {
console.log(`Savepoint 4: ${err}`);
return download("error-data C");
})
/* stage 3 */
.then(data => {
console.log(`Savepoint 5: ${data}`);
})
.catch(err => {
console.log(`Savepoint 6: ${err}`);
})
此時的輸出順序就會是
Savepoint 1: Fulfill: data A
Savepoint 2: Something wrong
Savepoint 3: Fulfill: error-data B
Savepoint 5: Fulfill: data C
更多資料請參考 MDN - Promise
fetch API
ES 6 提供了 fetch API, 就像是上面的 download 的實作, 只是是由瀏覽器提供的WebAPI:
const result = fetch(url, {
method, // HTTP Method, default 為 get
headers, // HTTP 表頭, default為null
body, // 內容, default為null
...moreOptions
});
result
.then(e => {
return e.json() //把資料以JSON格式解讀
})
.then(json => {
console.log(json)
});
這就是最常用來抓取伺服器資料的方法,比方說上面那個抓取政府運輸資料的程式可改為:
const domain = 'ptx.transportdata.tw';
const apiPath = 'MOTC/v2/Bus/StationGroup/InterCity';
const query = '$top=3&$format=JSON';
const targetUrl = `https://${domain}/${apiPath}?${query}`;
fetch(targetUrl)
.then(res => res.json())
執行結果
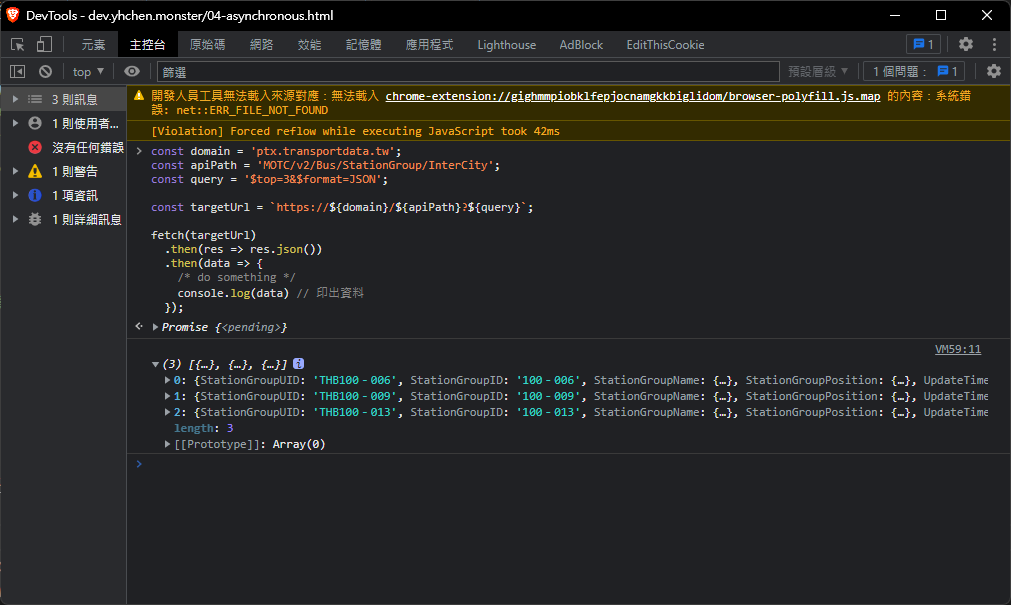
如果請求的站點出現404 NOT FOUND, 那麼當次 fetch 的狀態是 fulfilled
因為 fetch 象徵的意義是對伺服器發出請求, 而不是取得資料, 而404 status一樣是伺服器的回傳結果
fetch("httpp://www.google.com")
.then(d => {
console.log(true);
})
.catch(err => {
console.log("Error")
}) //進入 catch
這個例子中,誤把 http 打成 httpp,一個未知的協定,因此無法發出請求
導致直接進入 catch 階段
const domain = 'ptx.transportdata.tw';
const apiPath = 'MOTC/v2/Bus/StationGroup/InterCity';
const query = '$top=3&$format=JSON';
const targetUrl = `https://${domain}/${apiPath}?${query}`;
fetch(targetUrl)
.then(res => {
return res.text(); // 這次不使用 json(),而是使用 text() 取得未 paese 的內容
})
.then(content => {
console.log(content);
return JSON.parse(content+'}');
})
.catch(err => {
// 會進入這裡,因為在 content 後加上 '}',導致無法順利解析成JSON格式
console.log("Parse error")
})
而上述的例子中,可以觀察到在 then 或是 catch 中 throw Error,會進入下個階段的 catch
更多資料請參考 MDN - fetchAPI
async 與 await
在前兩個章節, 了解了 Promise 的使用方法, 但是 Promise 的回傳值永遠都是 Promise
因此要使用fetch到的資料, 還是有點麻煩:
// Sol 1:在 promise 內部使用 data
fetch(url)
.then(res => res.json())
.then(data => {
useDataA(data);
});
// Sol 2:使用 setInterval,每隔一段時間檢查a的狀態
let a;
fetch(url)
.then(res => res.json())
.then(data => {
a = data;
});
function useDataA() {
// 每隔 300ms 檢查一次
const timer = setInterval(() => {
// a 就緒了,清除計時器
if(a) {
clearInterval(timer)
/* do something */
JSON.parse(a);
};
}, 300)
}
對於大多數開發人員, 從 event 轉移到 Promise 已經是很好的情況了
但是在 ES 7, 接續推出了 async function
async function add(a, b) {
return a + b;
}
let result = add(a, b);
console.log(a) // Promise object
可以在 function 前,加上async 關鍵字,指示該函式成為非同步函式
非同步函式有兩個特色:
- 回傳值永遠都是 Promise 物件
- 允許使用
await
回傳值永遠都是 Promise 物件的意思是, 不論 return 什麼值, async function 都會包裝成 Promise
async function add(a, b) {
return a + b;
}
let result = add(10, 20); // Promise Object, [[value]] = 30
result.then(value => console.log(value)) // print: 30
特色1: 指示某個function是非同步事件, 所以使用Promise封裝
重點是特色2
await 可以取出 Promise 最後的回傳值,比方說:
function return100() {
return new Promise((resolve, reject) => resolve(100));
}
// 正常使用:
return100()
.then(data => console.log(data)) // print 100
// 在 async function 中使用 await
async function get100() {
const result = await return100();
console.log(result) // print 100
}
async function 可以讓的非同步程式"看起來"像同步程式
如果以上面那個download A、B、C 的例子,就可以改成
function download(url) {
return fetch(url)
.then(res => res.text());
}
async function processData() {
const dataA = await download(siteA);
const dataB = await download(siteB);
const dataC = await download(siteC);
}
如上所示, processData的行為就像是同步程式
await 對應到 then 方法, 那麼 catch 呢?
直接使用 try { ... } catch { ... } 即可
async function processData() {
try {
const dataA = await download(siteA);
const dataB = await download(siteB);
const dataC = await download(siteC);
} catch {
console.log("Download Failed");
}
}
這就是 async/await 的使用方法
更多資料請參考 MDN - async function
常用技巧與函數
這個部分, 統整了一些常用的 JavaScript 函式及語法
解構賦值
解構賦值的概念是, 如果被引用的值屬於物件或是陣列, 可以用同樣結構的宣告, 把值取出來:
const point = {
x: 10,
y: 20,
z: 30
}
const { x, y, z } = point;
// x = 10 , y = 20 , z = 30
也可以使用別名的方式, 比方說
const point = {
x: 10,
y: 20,
z: 30
}
const { x: a, y: b, z: c } = point;
// a = 10 , b = 20 , c = 30
// 稍微排序一下
// 對照 point 的宣告, a b c 剛好在 x y z 的值上
// 因此會宣告a, b, c 三個變數分別對應到x, y ,z
const {
x: a,
y: b,
z: c
} = point;
陣列也可以:
const arr = [1,2,3,4,5,6,7,8];
const [first] = arr;
// first = 1
// 可以解構更多的值:
const [a,b,c,d,e,f,g,h] = arr;
// a = 1, b = 2, c = 3, d = 4, e = 5, f = 6, g = 7, h = 8
引數也可以解構:
const point = {
x: 10,
y: 20,
z: 30
}
function getPoint({x, y, z}) {
console.log(x, y, z);
}
getPoint(point) // print 10 20 30
getPoint({x: 100, y: 200}) // print 100 200 undefined
即使物件多麼複雜, 只要有辦法宣告成同樣的形式, 都可以解構
const complexObj = {
a: {
b: {
c: {
d: 100
}
}
}
};
const { a: { b: { c: { d }}}} = complexObj
console.log(d) // print 100
// alias
const complexObj = {
a: {
b: {
c: {
d: 400
}
}
}
};
const { a: { b: { c: { d: myVar }}}} = complexObj
console.log(myVar) // print 400
展開運算子
可以使用 ... 運算子, 對物件或是迭代器進行展開:
陣列展開
let arr = [10, 20, 30, 40, 50];
let [first, ...data] = arr;
// first = 10
// data 則是把剩下的展開, data = [20, 30, 40, 50]
let [first, ...data, last] = arr //Error, 展開運算子必須得要放在最後
物件展開
const point = {
x: 10, y: 20, z: 30
}
const { x, ...other } = point
// x = 10
// other = { y: 20, z : 30 }
也可以在引數展開
function sum(a, b, c) {
return a + b + c;
}
const arr = [1, 2, 3];
sum(...arr); //會展開成 sum(1, 2, 3)
反過來, 也可以在參數展開
function sum(...numbers) {
let res = 0;
for(let i = 0; i < numbers.length; ++i)
res += numbers[i];
return res;
}
sum(1,2,3,4,5,6); // return 21
進階用法
可以用來拷貝一層 array (請注意, 該方法不是深拷貝, 僅是拷貝一層陣列而已)
let arr = [1,2,3,4,5,6,7,8];
let arr2 = arr;
let arr3 = [...arr]; // 展開 arr
console.log(arr === arr2); // true
console.log(arr2 === arr3); // false
也可以用來合併物件 or 陣列:
let obj1 = {
x: 10,
y: 20
}
let obj2 = {
a: true,
b: false
}
let obj3 = { ...obj1, ...obj2 };
console.log(obj3)
/* {
x: 10,
y: 20,
a: true,
b: false
} */
let arr = [1,2,3];
let arr2 = [2,3,4];
let arr3 = [...arr, ...arr2] // [1,2,3,2,3,4]
let arr4 = [...arr,...arr,...arr2,...arr]// [1,2,3,1,2,3,2,3,4,1,2,3]
/* 初始化物件的技巧 */
const defaultValue = {
x: 100,
y: 200,
z: 300,
}
const obj = {
...defaultValue,
z: 400
}
// obj = { x: 100, y: 200, z: 400 }
/* 要注意展開的順序 */
const obj = {
z: 400,
...defaultValue,
}
// obj = { x: 100, y: 200, z: 300 }
// 因為 defaultValue 後展開, 所以把原本的值又蓋掉了
物件迭代器
在 Object.prototype 中, 提供了幾種實用的方法
const obj = {
x: 10,
y: 20,
a: true,
b: false
};
let objKeyIter = Object.keys(obj); //回傳迭代器
for(const key of objKeyIter) {
console.log(key) // 依序印出 x, y, a, b
}
for(const value of Object.values(obj)) {
console.log(value) // 依序印出 10, 20, true, false
}
for(const pair of Object.entries(obj)) {
console.log(pair[0], pair[1])
// 依序印出:
// x 10
// y 20
// a true
// b false
}
/* 當然, 上面的用法可以合併解構附值 */
for(const [key, value] of Object.entries(obj)) {
console.log(key, value) // 結果同上
}
/* 前面有提到, 迭代器可以被展開 */
let keys = [...Object.keys(obj)] // ['x', 'y', 'a', 'b']
let value = [...Object.values(obj)] // [10, 20, true, false]
let entries = [...Object.entries(obj)]
/*
[
['x', 10]
['y', 20]
['a', true]
['b', false]
]
*/
/* 使用 fromEntries 還原物件 */
const o = Object.fromEntries(entries) // o = obj
此外, 諸如string 等也有實現迭代器, 因此
console.log(...'hello,world') //輸出 h e l l o , w o r l d 共11個字元
短路求值以及 ?? 運算子
在 JavaScript 中, boolean 判斷主要分為 falsy 和 truthy
falsy 的意義是, 在判斷式中會被當成 false 的值, truthy 則反之
只需要記得 falsy 就好, falsy的值有:
- false
- 0
- -0
- 0n (bigint)
- "", '', `` (空字串)
- null
- undefined
- NaN
- document.all
其餘的都是 Truthy 值
而看到的 || 和 && 運算子, 其真正的定義如下:
let res = A || B //若 A 為false, 才執行 B 敘述
/* Example */
let res1 = 100 || 'string' || console.log(100) // 100 是 truthy, 後面不必判斷了, 短路求值
let res2 = 0 || 'string' || console.log(100) // 0 是 falsy, 'string' 是 truthy, 短路求值
let res3 = A() || B() || C() // 若 A() 回傳 truthy 值, 則B、C 不執行
/* 以下與 res3 等價 */
if(!A()) {
if(!B()) {
C()
}
}
let res = A && B //若 A 為truthy, 才執行 B 敘述
/* Example */
let res1 = false && 0 && console.log(100) // false 是 falsy, 短路求值
let res2 = true && 0 && console.log(100) // true 是 truthy, 0 是 falsy, 短路求值
let res3 = true && 100 && console.log(100) // 前面兩個都是 truthy, 執行 console.log
let res4 = A() && B() && C();
/* 以下與 res4 等價 */
if(A()) {
if(B()) {
C();
}
}
?? 空值合併運算符比較特殊, 他會排除nullish(null 或是 undefined)來判斷求值
let value1 = 0 || 100; // value = 100
let value2 = 0 ?? 100; // value = 0, 因為 0 不是 nullish
let value3 = null ?? 100; // value = 100
let value4 = undefined ?? 100; // value = 100
let value5 = '' || 'default string' // value = 'default string'
let value6 = '' ?? 'default string' // value = '', 因為 '' 不為 nullish
?. 可選鏈式運算子
假設有個函式:
async function findOrEmpty() {
const res = await fetch(urlWithId) // 回傳的結果有可能為 null, 找不到 Id
// 1. { id, userData: ... }
// 2. 沒找到, null
// userData 的格式可能為 { name: string, age: number } 或是忘記填為 null
// 需要回傳 user 的名字
return res.userData.name;
}
上面的函式有個重大錯誤, 那就是 res 有可能是 null, 那執行 res.userData 相當於存取 null 的 userData 屬性
res.userData 也有可能是 null, 導致相當於存取 null 的 name 屬性
這會導致 Error 被擲出, 因此需要進行檢查, 比方說:
async function findOrEmpty() {
const res = await fetch(urlWithId)
let name = 'DEFAULT';
if ( res ) {
if ( res.userData ) {
name = res.userData.name
}
}
return name;
}
學會了短路求值, 可以使用:
async function findOrEmpty() {
const res = await fetch(urlWithId)
let name = 'DEFAULT';
if( res && res.userData )
name = res.userData.name;
return name;
}
而 ?. 運算子則允許存取一個可能為nullish的數值, 並當遇上nullish時, 回傳undefined 並且中止求值
async function findOrEmpty() {
const res = await fetch(urlWithId)
// 如果 res = null, 直接回傳 undefine
// 並中止對 res.userData、res.userData.name 求值
return res?.userData.name;
}
已經知道遇上 nullish 會回傳 undefined, 上面使用預設值的寫法可以改成:
async function findOrEmpty() {
const res = await fetch(urlWithId)
return res?.userData.name ?? 'DEFAULT'; // 使用空值合併運算子, 給予初始值
}
參考 ?? operator 和 Optional chaining
陣列
在 JavaScript 中, 陣列的方法算是極度常用的, 這裡只說明幾個常用的 Function:
先假定原始資料:
const users = [
{
name: 'Peter',
age: 20,
salary: 3800
},
{
name: 'Mary',
age: 22,
salary: 4000
},
{
name: 'Jason',
age: 30,
salary: 8900
},
{
name: 'Benson',
age: 45,
salary: 7000
},
{
name: 'Neil',
age: 35,
salary: 5200
},
]
陣列大部分的參數, 都是接受一個簽章為:
function callback(element, index, arr) {
console.log(element, index, arr);
}
的方法, 三個參數分別是
- 當前元素
- 當前元素索引
- 原始陣列
map() 轉換原始陣列變成另外一個陣列
let data = users.map( e => {
return e.salary
});
console.log(data) // [3800,4000,8900,7000,5200]
Note! 有個很接近的方法叫做 forEach, 但是不建議使用, 他算是 for-loop 的callback版本
for(let i = 0; i users.length; ++i) {
console.log(`index = ${i}, value = ${users[i]}`);
}
//等同
users.forEach((e,i) => {
console.log(`index = ${i}, value = ${e}`);
})
let data = users.forEach((e,i) => {
return e.salary
})
console.log(data) // undefined, forEach不回傳陣列
因為 forEach 可以被 map 取代, 且 forEach 不回傳陣列, 因此會有人用來修改原始陣列, 比方說
users.forEach((e,i, arr) => {
arr[i] = e.salary;
})
這不是一個好做法, 因此不推薦使用 forEach
此外, 早期還未出現展開運算子之前, 可以用 map 複製陣列
// const data = [...arr]
const data = arr.map(e => e);
filter() 過濾原始陣列
let data= users.filter((e) => {
return e.age > 30; // 必須回傳 boolean 值
})
console.log(data) /* data = [
{
name: 'Benson',
age: 45,
salary: 7000
},
{
name: 'Neil',
age: 35,
salary: 5200
}
] */
every() 以及 some() 判斷所有陣列
const flag1 = users.every(e => e.salary > 5000) // false, 因為有人薪水不足 5000
const flag2 = users.some(e => e.salary > 5000) // false, 因為有人超過 5000
every 的概念相當於C++的 all_of(全部符合), some 則是 any_of(任一符合)
sort 進行排序
users.sort((a,b) => a.age - b.age) // 根據 age 排序
users.sort((a,b) => a.name.localeCompare(b.name)) // 根據 name 排序
// string 要使用 string.localeCompare 進行比較
slice 進行分割
// users.slice(startIndex, count)
users.slice(0, 2) // 從index 0 開始, 取出兩個元素
find 傳入條件式, 尋找元素
// 因為 find 不一定會找到, 建議使用 ?. 來存取物件
const name = users.find(e => e.age === 22)?.name
在實例上, 會建議通過一系列的轉換, 取出所需要的資料, 比方說:
const users = [
{
name: 'Peter',
age: 20,
salary: 3800
},
{
name: 'Mary',
age: 22,
salary: 4000
},
{
name: 'Jason',
age: 30,
salary: 8900
},
{
name: 'Benson',
age: 45,
salary: 7000
},
{
name: 'Neil',
age: 35,
salary: 5200
},
{
name: 'Howard',
age: 44,
salary: 6666
},
{
name: 'Alex',
age: 35,
salary: 7777
},
]
const salarySigma = users
.filter(e => e.salary > 5000)
.map( e => e.salary )
.reduce((sum, currentValue) => sum + currentValue, 0);
console.log(salarySigma) // 35543
const salaryAvg = salarySigma / users.filter(e => e.salary > 5000).length // 7108.6
通過一系列的轉換函式, 取出所需要的資料
絕大部分的 Web 應用, 都是處理資料的轉換, 因此字串、陣列相關的方法, 幾乎是必備的知識
反過來說, 雖然也有情況要進行CPU的密集計算, 但是該情況還是相對比較少的
前面提到的用法, 幾乎涵蓋大部分陣列的使用情境, 但也建議稍微看一下 String.prototype 跟 RegExp.prototype 的資料
其中 RegExp 是 Regular Expression 正規表示法的意思, 允許使用模式來匹配字串, 舉例來說:
// 假定輸入的資料是日期格式, 且有可能是 YYYY-MM-DD 或是 YYYY/MM/DD
const date1 = "2001-01-05";
const date2 = "1998/01/02";
const rule = /(?<year>[0-9]{0,4})[\-\/](?<month>[0-9]{0,2})[\-\/](?<date>[0-9]{0,2})/;
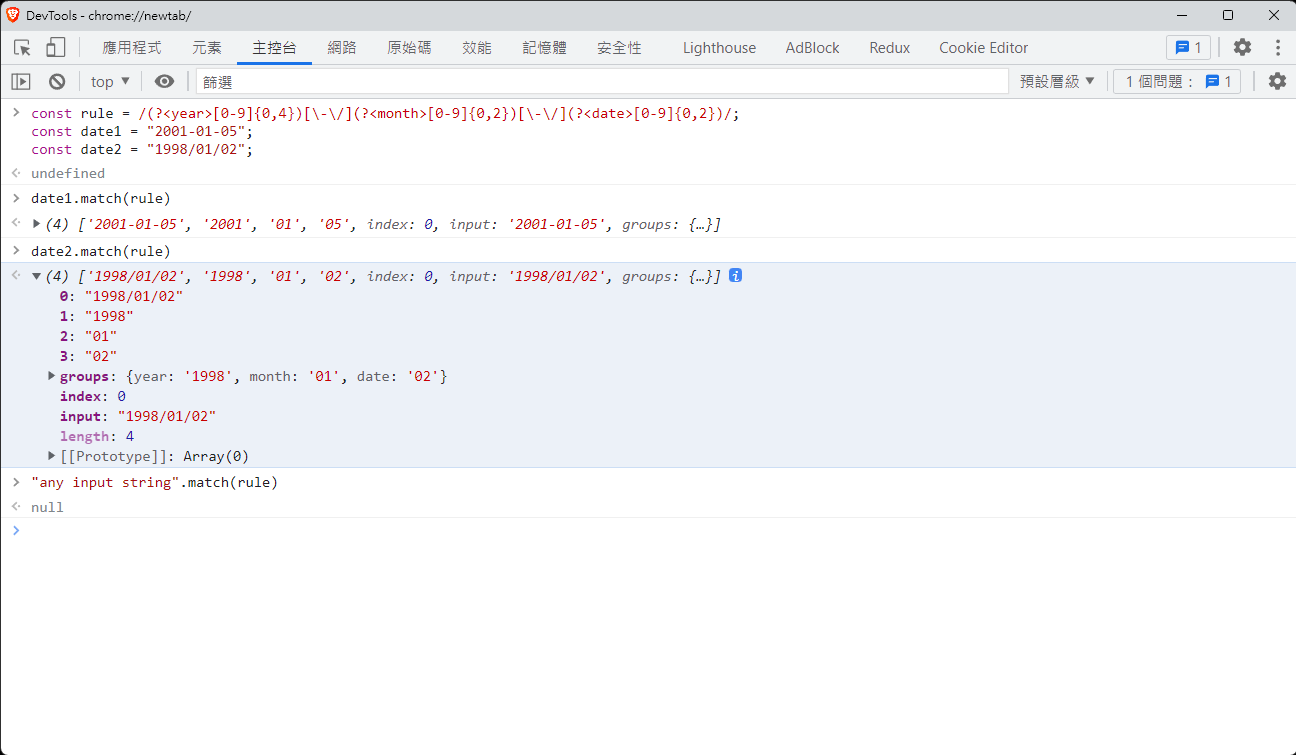
這只是一個很小的範例, 還有很多種用法, 比如說:驗證電子信箱、網址格式、特定的文字輸入...等, 且上方的RegExp 是有小瑕疵的(你可以嘗試找出來!)
總之, 字串與陣列的處理, 涵蓋大部分的操作情境, 且額外要注意的事情是:一些 ArrayLike 物件, 若有實現迭代器, 也是可以輕鬆轉換成陣列的
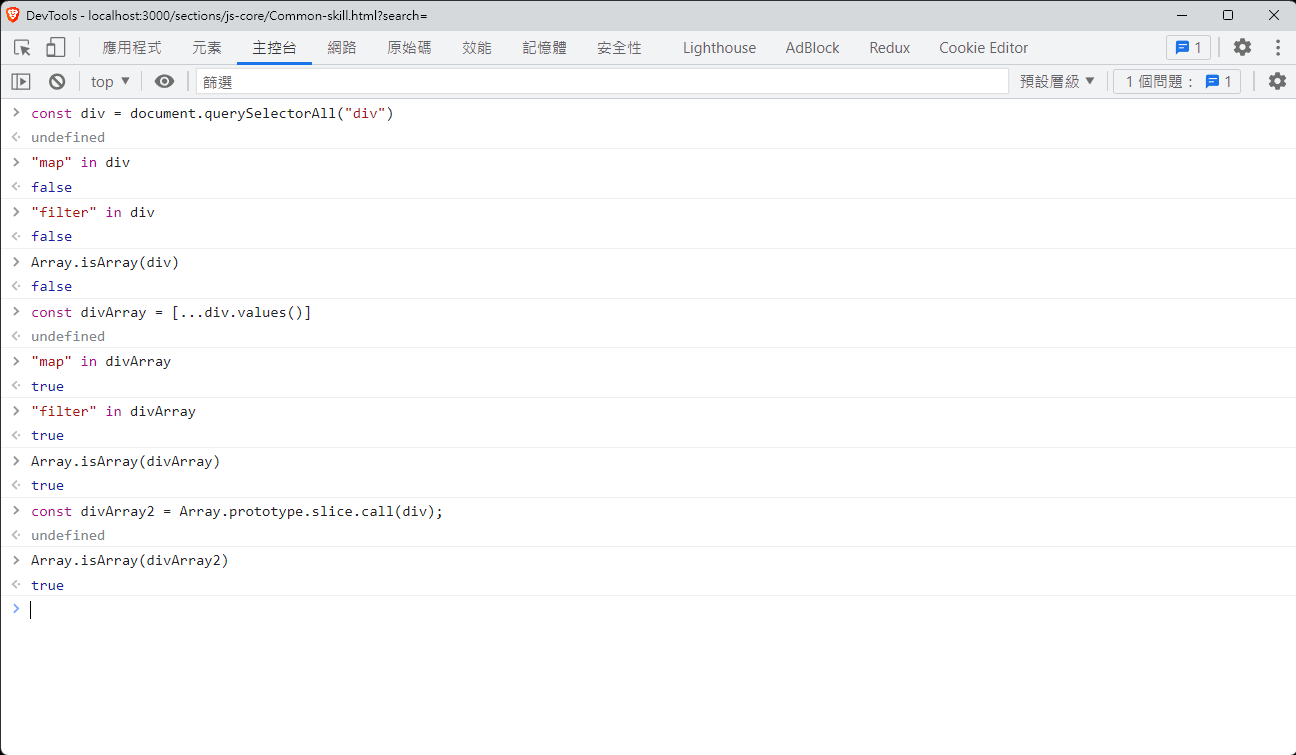
querySelectorAll 回傳的結果是 NodeList, 他並沒有陣列的成員或是屬性, 也無法通過 Array.isArray 的測試;
但是經過迭代器展開, 或是早期的轉換方式 Array.prototype.slice.call 後, 就成為了陣列型別
這些"像是"陣列樣子的物件, 被稱作 ArrayLike, 除了陣列本身是ArrayLike(因為陣列算是一種特殊的物件, JavaScript沒有真正意義的原生陣列), 還有String也是很經典的例子
JSON的序列化/反序列化
/* 反序列化 */
const strLikeJson = '{ "a":100, "b": 200, "c" : 3000 }';
const object = JSON.parse(strLikeJson);
/**
* object {
* a: 100,
* b: 200,
* c: 30000
* }
*/
/* 序列化 */
const str = JSON.stringify({ a: 10, b: 20, c: 30 });
// string '{"a":10,"b":20,"c":30}'
JSON.parse 用來把 JSON 字串轉換為 JS物件, 且一定要是 JSON字串, 這個說法有一點模糊, 看下面的例子
const str1 = "{ a: 10, b: 20 }";
const str2 = "{ a: 10, b: 20, }";
const str3 = "{ 'a': 10, 'b': 20 }";
const str4 = "{ \"a\": 10, \"b\": 20 }";
在上述的例子中, 只有 str4 是合法的 JSON字串
JSON.parse 可以接受第二個參數 reviver function, 在 parse 解析完字串後, 可以進行一些修改:
const jsonStr = '{ "a":100, "b": 200, "c": 300 }';
let a = JSON.parse(jsonStr, (key, value) => {
console.log(key, value);
if(typeof value === "number")
return value + 50;
return value; // return origin value
});
// a = { a: 150, b: 250, c: 350 };
這允許在解析的同時進行一些修改或檢驗, 但是要注意, 最後一個解析會收到 key 為空字串結果, 雖然沒有特別註記, 但筆者猜測應該是告知開發者, Parse 結束的情況
如果 reviver 中沒有回傳值為 undefined, 則會刪除該屬性:
const jsonStr = '{ "a":100, "b": 200, "c": 300 }';
let a = JSON.parse(jsonStr, (key, value) => {
switch( key ) {
case "a":
case "b":
break;
default:
return value;
}
});
// a = { c: 300 };
如果當次解析的物件是巢狀的, 則由深到淺解析
JSON.parse('{"a":{"b":{"c":{"d":true}}}}', (k,v) => { console.log(k); return v});
// output: d c b a
JSON.stringify 則是會把物件轉換成對應的 JSON字串, 優先調用 toJSON 方法, 然後把 可列舉 跟 可序列化 的屬性進行轉換
- 可列舉:PropertyDescriptor 中 enumerable 為 true 的屬性
- 可序列化:例如 function, 就不可進行轉換, 通常僅轉換:
string,boolean,number;如果屬性是陣列或物件, 則深入檢查
JSON.stringify 可以額外接受兩個參數, 第二個參數是 replacer, 可以是function 或是 array:
const foo = {
foundation: "Mozilla",
model: "box",
week: 45,
transport: "car",
month: 7
};
const jsonStr = JSON.stringify(foo, (key, value) => {
/* replacer 為 Function 時, 如果 return 的值是 undefined, 則忽略該值 */
if (typeof value === "string") {
return undefined;
}
return value;
});
// jsonStr = '{"week":45,"month":7}'
/* replacer 為 array 時, 僅保留對應的key */
const jsonStr2 = JSON.stringify(foo, ['model', 'month', '??']);
// jsonStr = '{"model":"box","month":7}'
第三個參數是 space 只是控制縮排而已, 例如在輸出文件時, 可以使用 JSON.stringify(obj, null, 4) 保留 4個space 的縮排
匿名函數
當調用 Lib 的 function, 且內部調用極深時, 可以再某個地方使用 function(){} 而不是 () => {}
這裡使用 setTimeout() 來說明:
setTimeout(function myFn(){
throw new Error();
}, 0)
/* Error stack:
Uncaught Error
at myFn (<anonymous>:2:9)
*/
setTimeout(() => {
throw new Error();
}, 0)
/* Error stack:
Uncaught Error
at (<anonymous>:2:9)
*/
若自己開發Library, 或是使用了較深的function invoke, 可以加上 function name(){} 來進行除錯, 比方說:
lib(function myFn(){
/* do something */
})
/* Error stack:
Uncaught Error
at (<anonymous>:2:9)
at (<anonymous>:2:9)
at myFn (<anonymous>:2:9) <---- 也許某個部分會原本的函式名稱
at (<anonymous>:2:9)
at (<anonymous>:2:9)
at (<anonymous>:2:9)
at (<anonymous>:2:9)
at (<anonymous>:2:9)
*/
// 反之, 若使用 arrow function:
lib(() => {
/* do something */
})
/* Error stack:
Uncaught Error
at (<anonymous>:2:9)
at (<anonymous>:2:9)
at (<anonymous>:2:9)
at (<anonymous>:2:9)
at (<anonymous>:2:9)
at (<anonymous>:2:9)
at (<anonymous>:2:9)
at (<anonymous>:2:9)
會完全遺失錯誤堆疊的資訊
*/
結論
這裡統整一下目前的內容:
- JavaScript 的基本語法
- JavaScript 中的型別系統
- 早期的物件與現代化的語法
- JavaScript 內部引擎的運作機制
- 非同步程式:Promise與 async/await
- 常用的函式
這裡釐清一個問題, JavaScript Core 到底指的是什麼部份呢?
可以參考 MDN 的 Standard Built-in Object, 基本上就是 JavaScript 的核心, 常用的部分為:
- Infinity、NaN、undefined 等屬性值
- Global Function
- isFinite()
- isNaN()
- parseFloat()
- parseInt()
- encodeURI()
- encodeURIComponent()
- decode()
- decodeURIComponent()
- Global Object
- Number
- BigInt
- Math
- Date
- String
- RegExp
- Indexed Collections
- Array
- Typed-Array (參考 MDN, 就是限制每個元素幾個位元的陣列, 類似C的靜態型別)
- Keyed Collections
- Map、WeakMap
- Set、WeakSet
- 結構化資料
- JSON
- ArrayBuffer、SharedArrayBuffer
- Atomics
- DataView
- 控制抽象物件
- Promise、Generator
- Reflection
- Proxy
- Reflect
- 各種 Error 物件
最核心的部分是 Global Object 以及 Array、JSON、Promise
而 ArrayBuffer 如果處理檔案上傳或是 WebSocket, 也有機會使用到
WebGL 的應用也常常使用到 TypedArray
不屬於 JavaScript Core 的部份
Web API
在 Overview 有提到, JavaScript 可以運行在瀏覽器以外的環境(Node.js), 這情況下, 通常會當作伺服器運行
而由瀏覽器提供的一系列JavaScript函式或物件, 被稱作Web API, 這裡提出幾個常用的:
- Window: 一個包含 DOM 文件的視窗, 可以說是瀏覽器物件模型(BOM), 得以透過 JavaScript 跟瀏覽器進行互動:
- history:與瀏覽紀錄的歷史有關
- location:當前頁面的網址資訊
- screen:目前的視窗資訊
- navigator:瀏覽器本身的資訊, 像是版本號、運行平台等
- Document: 處理 DOM Tree, 包含HTML、XML、SVG 等類型;或是像 Cookie 等資料, 象徵
瀏覽器中載入的網頁資訊
Web API實在是有太多部份, 例如WebSocket、WebRTC(即時影音通訊)、剪貼簿、事件目標、audio/video 處理模組 ... 等
Nodejs
相對於 Web API, 伺服器端的 JavaScript (Node.js) 不需要處理瀏覽器相關的功能, 但是要求直接存取系統上的資源:
- node:crypto:加密/解密模組
- node:http:HTTP協定相關模組(發送請求、開啟伺服器等)
- node:process:有關目前運行的Process(行程)資訊
- node:os:作業系統相關的資訊
- node:fs:檔案系統的操作介面
- node:net:底層TCP、IPC的操作介面
- node :dgram:底層UDP的操作介面
- C++ Addons:與C++ Library 交互的一系列操作模組
如上所列, Nodejs專注在系統相關的操作, 以及如何與 C++ 進行溝通, 反而一些通用格式的解析器(如XML、SVG)或是影音模組並沒有提供
所以 JavaScript 其實可以分成兩部份:
- Standard Object + Web API = 瀏覽器上的JavaScript
- Standard Object + Nodejs API = 伺服器端上的JavaScript
而 Web API、Nodejs API 這些又被稱為宿主環境(Host Environment), 因為他們是由 Runtime Environment 提供者給予的操作介面
HTTP

HTTP 全名為 Hyper Text Transfer Protocol 超文字傳輸協定
紀錄於 RFC 2616
以及衍生的 HTTPS、HTTP/2 等協定
相信各位在計算機網路概論都有學習過該協定的內容, 因此這裡只會進行一些補充
以及一些伺服器相關的實作
請注意, 如 HTTP Pipeline 之類的細節不在本章範疇, 預設你已經在計算機網路概論學習過了
User-agent
泛指能夠發出請求的工具, 通常由瀏覽器協助處理。而一些情況下, 如開發人員的Debugger、爬蟲腳本等, 也算是 User-agent
由瀏覽器發出的請求, 通常會受到一些限制(不像自己撰寫的Request 那麼自由), 常見的工具有
- curl
- wget
- python、javascript、php 的腳本
那在 linux 系統上, 還有如 nc 等工具, 可以建立 Raw TCP 連線, 輸入 HTTP 請求文:
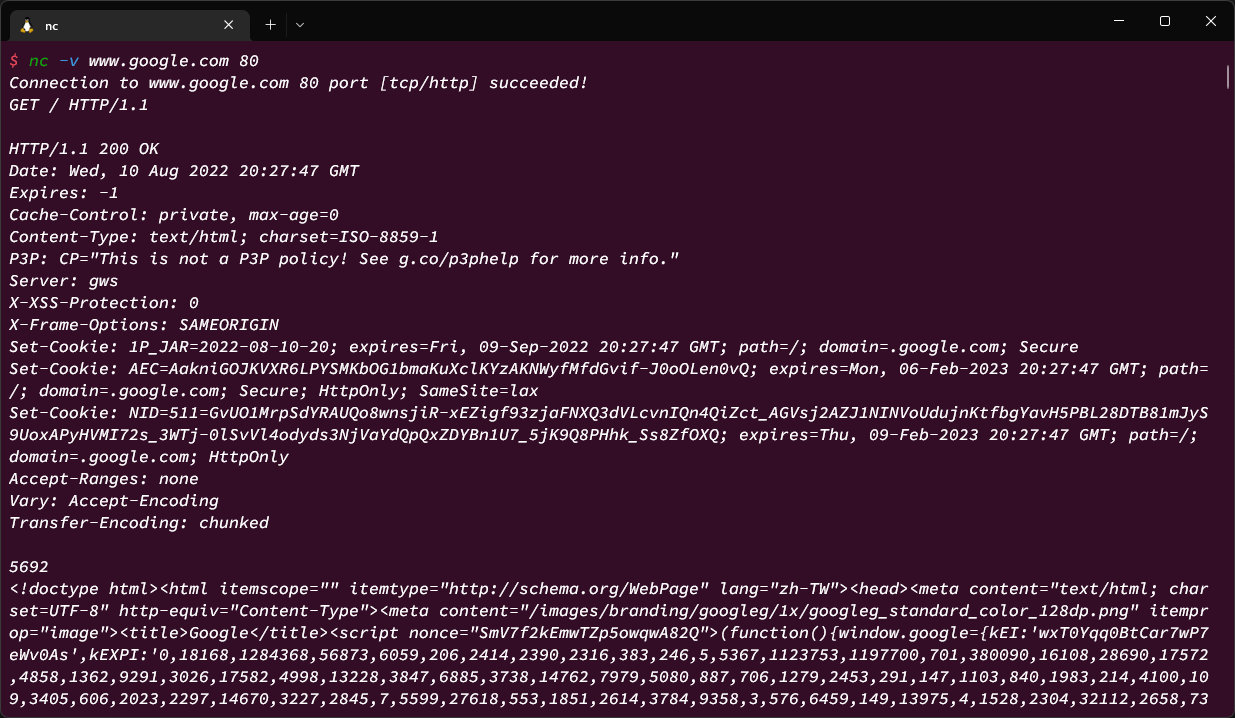
HTTP 請求格式
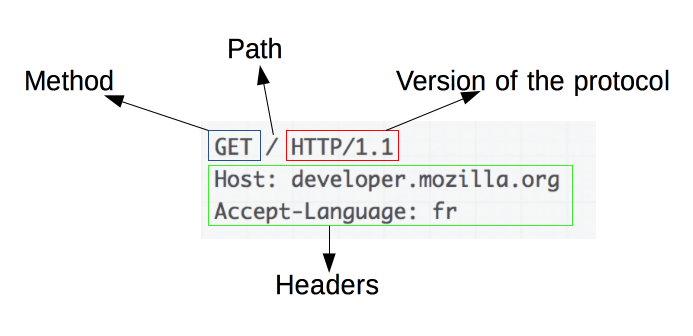
請求會由以下幾個元素組合而成:
- HTTP 動詞
- 請求路徑
- HTTP 協議版本
- headers
- 請求內容
HTTP 的 Header 可以見 MDN: HTTP Headers
這裡只提幾個重要且常見的 Header:
- Authorization:添加認證資訊
- Content-type:告知接收方, 請求內容的格式
- X-*:自定義的表頭
這裡特別要提及的是 Content-type, 在REST 章節中, 有強調資源的表達, 就是透過該表頭
比方說 JSON 格式的資料, 會透過 content-type: application/json
一般的表單提交, 通常會會是 application/x-www-form-urlencoded 或是 multioart/form-data
在以前, 比較少處理檔案的提交, 因此使用 application/x-www-form-urlencoded 即可, 他會把表單用類似 Query String 的方式封裝
如果有個表單要輸入:帳號、密碼、電子信箱, 那封裝後的資料格式為
account=myacc&password=a12345678&[email protected]
HTTP 回應格式
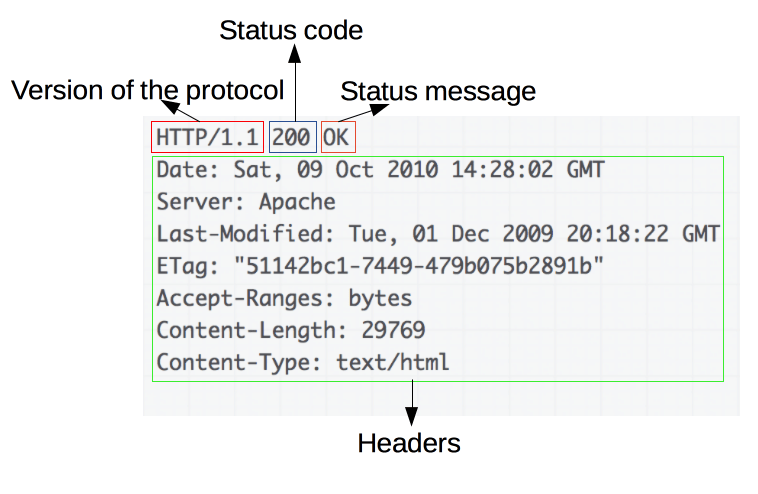
響應內容會由以下幾個元素組合而成:
- HTTP 協議版本號
- status code, 告知對應請求的成功或失敗, 以及原因
- status message, 描述訊息, 可以由伺服器端指定
- HTTP headers(與請求相似)
- 回應主體
Content-type 重要的原因為, 他指明了資源是以何種模式傳送, 即使今日我發明了某種特殊的格式 my-packed
只要伺服器端擷取 content-type 表頭, 就可以知道應該以什麼樣的方式來存取資源
比方說實現一個伺服器, 並把回傳表頭設定為 text/plain, 而不是 text/hmtl
這將會使得瀏覽器不把回傳內容當成 HTML 處理, 因此會顯示:
而非平常看到的網頁形式
要注意的是, 在瀏覽器上看到的一切, 都是瀏覽器處理的
比方說HTML文字, 瀏覽器會繪製成精美的畫面;
使用 VSCode 打開, 舊只是一連串的文字;
請注意某些行為, 是由瀏覽器幫你完成的
HTTPS
在這裡, 要特別提及的事情是 HTTPS 為什麼要特別提呢?
原因是因為, HTTPS的站點與HTTP的站點瀏覽器的行為會不一樣
這是因為, HTTPS的站點瀏覽器會啟用 Secure Contexts
而一般的HTTP的站點, 會被限制某些 Web API, 比方說 麥克風或是PWA的功能
以 Google Meeting 的功能來說, 像是直播畫面、語音通話, 在HTTP站點是不可能的
Web API 中, 有某些特別的 APIs, 包含:
- 需要用戶端設備的訪問權限
- 針對特殊數據的訪問, 如用戶憑證
就不允許在 HTTP 站點中使用
在 MDN 的 API 說明中, 也會特別註記 
更多資訊參考 Secure Contexts
而有時候, 會感覺 HTTPS 的站點好像比較快
這也不是錯覺, 因為 HTTPS 部分可能會啟用 HTTP/2 或是 SPDY 協議, 因此不會限制併發數量
HTTP站點會限制同網域的最大併發數量, 請見這裡
不過當使用 localhost 時, 則不受到此限制, 因為是透過 loopback 位址(127.0.0.0/8 or ::1/128)進行處理
章節回顧
本章節把 HTTP 比較容易遺漏的部分看過一次, 並指出HTTPS站點的行為與HTTP站點是不同的
- HTTP 的用戶端組成
- Content-type 的重要性
- 瀏覽器的 Secure Contexts
URL
在討論 URL 之前, 先來看常見的三個定義:
- URI - Uniform Resource Identifier, 意指用於標識某一網際網路資源名稱的字串
- URL - Uniform Resource Locator, 俗稱網頁位址, 簡稱網址, 是網際網路上標準的資源的位址
- URN - Uniform Resource Name, 期望為資源提供持久的、位置無關的標識方式
大概可以理解為 URI = URL + URN, 這裡不深入探討三者的差異
但是以現今的用法來說, URI 可以看作和 URL 等價, URN 則是獨立的用法
URL 的形式
URL 通常會表現為如下的形式:
hierarchical part
┌───────────────────┴─────────────────────┐
authority path
┌───────────────┴───────────────┐┌───┴────┐
abc://username:[email protected]:123/path/data?key=value&key2=value2#fragid1
└┬┘ └───────┬───────┘ └────┬────┘ └┬┘ └─────────┬─────────┘ └──┬──┘
scheme user information host port query fragment
在該例子中:
- abc 是協定名稱
- username 是用戶
- password 是密碼
- example.com 是網域
- 123 是連線的 port
- /path/data 是路徑
- ?key=value&key2=vale2 是查詢字串
- fragid1 是 fragment
而常見的
https://www.google.com
若未指定通訊埠(之後都稱 port ), http 使用 80 port, https 使用 443 port
請注意, URL 不一定只用在 HTTP 協議上, 比方說 mysql 或是 postgresql 可以使用 URL 的方式登入
- 用戶名稱為 Nero
- 密碼為 a1234qwer
- 伺服器位於 test.database.cc 所指向的 IP
- 使用 5432 port
- 資料庫名稱為 mydatabase
那個可以使用
postgresql://Nero:[email protected]:5432/mydatabase
或是加上 Query 參數, 設定額外的資訊, 如
postgresql://Nero:[email protected]:5432/mydatabase?connect_timeout=10&application_name=myapp
而 username 和 password, 實務上比較少用到, 但是如果你想嘗試的話, 可以透過這種方法驗證:
- 在 github 或是 gitlab 上開啟 Repo, 並提交 initial commit
- git clone 該 repo
- git push, 此時終端機會請你輸入帳號、密碼
- 中止上個階段
- 使用指令
git remote set-url origin https://[username]:[password]@github.com/<repo> - 再次嘗試 push, 此時不必輸入帳號、密碼就可以完成驗證
跟 URL 有關的 API
在瀏覽器中, 有個URL物件, 可以用來解析基於 HTTPS 和 HTTP 的 URL
const str = "https://abc:[email protected]?key=1&v=2#test"
const url = new URL(str); /*
{
hash: "#test"
host: "dev.yhchen.monster"
hostname: "dev.yhchen.monster"
href: "https://abc:[email protected]/?key=1&v=2#test"
origin: "https://dev.yhchen.monster"
password: "passwd"
pathname: "/"
port: ""
protocol: "https:"
search: "?key=1&v=2"
searchParams: URLSearchParams {}
username: "abc"
}
*/
host與hostname有微小的差異, 出現在含有 port 的時候- host 包含 domain name + port, 例如
localhost:8080 - hostname 僅包含 domain name, 例如
localhost
- host 包含 domain name + port, 例如
origin包含了 protocol + host, 比方說https://localhost:8080href意思是指hyper refer超連結, 就是原本的輸入search包含了?還有之後的Queryhash包含了#還有之後的Fragment
通常來說, 查詢字串的形式為key=value, 並透過& 連結起來
可以用複雜一點的作法來 parse 查詢字串:
const str = "https://dev.yhchen.monster?key=1&v=2&g=25&k=40"
const url = new URL(str);
const query = url.search;
const entries = query.slice(1).split('&').map(token => token.split('='))
const queryObj = Object.fromEntries(entries);
不過各位學員其實可以注意到, URL物件有提供 searchParams 這個物件, 他提供了一些實用的方法
假設現在有個複雜一點的 Query String:
?key=1&v=2&g=25&k=40&qe=hello
透過以下的方法:
/* ... parse 結束 */
const params = URL.searchParams;
/* 迭代器家族 */
[...params.keys()] // result: ['key', 'v', 'g', 'k', 'qe']
[...params.values()] // result: ['1', '2', '25', '40', 'hello']
[...params.entries()] /* result:
[
["key","1"],
["v","2"],
["g","25"],
["k","40"],
["qe","hello"]
]
*/
/* 設值器 */
params.append('test', 'string');
// url.search: "?key=1&v=2&g=25&k=40&qe=hello&test=string"
params.append('test', 'test');
// url.search: "?key=1&v=2&g=25&k=40&qe=hello&test=string&test=test"
/* 取值器 */
params.get('key') // result: 1
params.getAll('test') // result: ['string', 'test']
params.get('test') // 取出第一個 result: 'string'
/* 覆蓋 & 刪除 */
params.set('test', '0')
// url.search: "?key=1&v=2&g=25&k=40&qe=hello&test=0"
params.delete('test')
// url.search: "?key=1&v=2&g=25&k=40&qe=hello"
同時, 可以透過 location.href 取得目前的網址
至於 Fragment, 是比較特殊的用法, 在之後幾個章節在說明
相對與絕對路徑
之前有提到過, 會透過 fetch API 抓取遠端的資料, 並且假定目前的網址為
https://www.example.com/docs/page/URL-intro
而 API 的端點位於 https://www.example.com/api/datas:
fetch("api/datas") // Errors
fetch("/api/datas") // It Works!
原因在於, 一開始的/ 會改變 URL 的參照, 使用 / 發出的請求, 會以 origin 作為 Base
而沒有使用 /, 則是以當前路徑作為參照點:
// Current Location: https://www.example.com/docs/page/URL-intro
fetch("api/datas") // 請求的URL為 https://www.example.com/docs/page/api/datas
fetch("/api/datas") // 請求的URL為 https://www.example.com/api/datas
這是一個需要注意的地方
章節回顧
該章節僅需要知道 URL 的構成語法, 以及瀏覽器中與 URL 有關的 API 即可
- URL 的組成
URL物件與location.href- 發出Request時, 相對路徑與絕對路徑的差異
什麼是API
本章節的一開始, 首先要釐清 API 的意思。API - Application Programming Interface
其代表的意義為應用程式的互動介面, Protocol、函式簽章等, 寬鬆意義上也可以說是 API
而另一方面的意義, 則是程式設計的相關實作
舉例來說:
- 需要使用 OpenGL 繪製, 會使用到
gl[FunctionName]- glVertex2f、glBegin、glEnd ... 等
- 透過URL抓取資料, 比方說:
http://www.example.com/data - 調用System Call, 如 C 語言的
#include<sys/*.h>等
重點在於介面 interface, 從資料結構、常數、函式, 到圖形化介面的按鈕
比方說同樣使用Postgresql資料庫, 可以寫一個JavaScript程式碼:
const { appendFileSync } = require('fs');
const { Client } = require('pg');
const conf = {/* Database connection infomation */}
const client = new Client(conf);
const command = `SELECT * FROM datas`;
client
.query(command)
.then({ rows } => {
const transfromData = rows.map( row => JSON.stringify(row));
appendFileSync('data.json', transfromData);
process.exit();
});
或者使用 shell 去存取:
psql -d mydatabase -U user --password
psql (12.11 (Ubuntu 12.11-0ubuntu0.20.04.1))
Type "help" for help.
user=# SELECT * FROM datas;
或許透過不同的方式去存取資料庫, 但是最終目的都是 從某個地方把資料讀出來, 而資料庫則是提供了客戶端的程式psql 或是相關的函式庫(libpg)
針對特定功能, 提供一系列操作的介面, 就是 API 的本質
Note! 請注意, 重點是介面
比方說 Firefox 與 Chrome 都有 console.log 來輸出一些資料在 DevTools 上
他們內部的實現不一定是相同的, 但都可以用 console.log 做到這件事情
Interface 至關重要
介面的概念非常重要, 因為介面隱藏了細節, 以生活的例子來說:
無論是電腦、電視、手機充電器、微波爐 ... 等家具, 都可以統一透過 110V 或是 220V 的插座使用
也許他們的功率分別是 700W、300W、65W、1200W, 但是對於電源輸入的介面, 所有的電器大抵上都是相同的
而對於程式的設計, 介面的重要性有幾點:
- 對於第三方開發人員來說, 他隱藏了內部的實現, 僅把操作的函式暴露出去
- 對於使用者來說, 提供了大致相同的操作方法
- 對於模組的規畫人員, 提供了一個好的設計模式
對於1、2點, 算是非常直白, 因此這裡著重在第3點
介面隔離原則 & 依賴反轉原則
雖然設計模式的理解在程式碼的開發上也相當重要, 但是這裡不打算細談, 只會提出這兩個重要的原則:
介面隔離原則 Interface Segregation Principle
拆分非常龐大臃腫的介面成為更小的和更具體的介面, 這樣客戶將會只需要知道他們感興趣的方法 從而容易重構, 更改和重新部署
依賴反轉原則 Dependency inversion principle
高層次的模組, 不應該依賴於底層的模組, 而是依賴於抽象介面;以及, 抽象介面不應該依賴於具體實現。而具體實現則應該依賴於抽象介面
這裡把兩個原則同時提出, 以下舉出兩個例子:
倘若我是資料庫的開發人員, 早期階段只有磁碟機時, 做出以下規劃:
class HardDisk {
public:
void write(char* content);
void read(char* filename);
/* more member */
}
現在, 處理好了設備的處理函式, 接下來實現資料庫本身的邏輯:
class DataBase {
public:
int connect(const std::string user, const std::string password);
void load(HardDisk disk);
void store(HardDisk disk);
/* more member */
}
// 成員可能的實作:
void DataBase::load(HardDisk disk) {
/* 根據連線資訊以及查詢指令, 匹配索引、資料庫、資料表等 */
disk.read(filename);
}
void DataBase::store(HardDisk disk) {
/* 建立 BTree、檢查索引、資料型別、格式化等 */
disk.write(content);
}
這看起來很不錯對嗎?但是隨著時間過去, 有了更多設備, 比方說SSD:
class SolidStateDisk {
public:
void write(char* content);
void read(char* filename);
/* more member */
}
class DataBase {
public:
int connect(const std::string user, const std::string password);
void load(HardDisk disk);
void store(HardDisk disk);
// function overload
void load(SolidStateDisk disk);
void store(SolidStateDisk disk);
/* more member */
}
好的, 現在解決了問題, 但是新的問題又出現了:SSD又分成PCIe、SATA、M.2 等介面, 於是可能會新增:
class SolidStateDisk_SATA {}
class SolidStateDisk_PCIe {}
class SolidStateDisk_M2 {}
而在 Database 類別中, 則要擴充更多成員函式, 這顯然會導致程式碼越來越難以維護...
這時候依照依賴反轉原則:
- 高層次的模組, 不應該依賴於底層的模組
- 以及, 抽象介面不應該依賴於具體實現
- 具體實現則應該依賴於抽象介面
首先釐清高層次與底層次的模組, 簡單來說, 越接近應用層(或是說商業邏輯), 就相對高階
DataBase 是高層次的;HardDisk 是低層次的
其次, 高階的模組不應該依賴於低層次的模組, 也就是說這種設計方式是有問題的
class DataBase {
public:
int connect(const std::string user, const std::string password);
void load(HardDisk disk);
void store(HardDisk disk);
void load(SolidStateDisk disk);
void store(SolidStateDisk disk);
/* more member */
}
處理的方式有很多種, 但是具體來說, 有個明確的目標:減少 DataBase 的依賴性
可以先提出一個高階介面, 且不提供具體的實現, 比方說
class IO_Device {
public:
virtual void write(char* content) = 0;
virtual void read(char* filename) = 0;
}
接下來, 移轉高階模組的依賴:
class DataBase {
public:
int connect(const std::string user, const std::string password);
// 依賴於 IO_Device 介面
void load(IO_Device disk);
void store(IO_Device disk);
// void load(HardDisk disk);
// void store(HardDisk disk);
// void load(SolidStateDisk disk);
// void store(SolidStateDisk disk);
/* more member */
}
最後, 修改低階模組的宣告, 使其必須實現高階介面:
class HardDisk: public IO_Device {}
class SolidStateDisk_SATA: public IO_Device {}
class SolidStateDisk_PCIe: public IO_Device {}
class SolidStateDisk_M2: public IO_Device {}
回頭來看的目標:
- 高層次的模組, 不應該依賴於底層的模組:DataBase 現在依賴於
IO_Device之上 - 以及, 抽象介面不應該依賴於具體實現:
IO_Device並未提供實作, 而是交由底層的模組實現 - 具體實現則應該依賴於抽象介面:
HardDisk與SolidStateDisk繼承 Pure Virtual Functionwrite與read
倘若未來, 想要再加入新的儲存媒介, 比方說使用記憶體 RAMDisk:
// 倘若未繼承 IO_Device, 便無法提供給 Database類別使用
class RAMDisk : public IO_Device {
// 因為繼承了 IO_Device, 必須實作兩個虛擬函式
void write(char* content);
void read(char* filename);
}
以上是一個很經典的例子, 另外一個例子式 C++ 的 STL, 試想一下:
有許多需要操作的容器, 以一維容器來說, 有 vector、list、queue、stack 等
假設他們都有排序的需求, 實作有可能有兩種情況:
void sort(std::vector, int startIndex, int endIndex);
void sort(std::list, int startIndex, int endIndex);
void sort(std::queue, int startIndex, int endIndex);
void sort(std::stack, int startIndex, int endIndex);
sort(vec, 0, vec.size() -1 );
或者是依賴於迭代器(Iterator)介面
template<typename T>
class Iterator<T> {
public:
virtual T* begin() = 0;
virtual T* end() = 0;
virtual operator--();
virtual operator++();
}
/* Impl interface Iterator<T> */
template<typename T> class std::vector<T> : public Iterator<T>{}
template<typename T> class std::list<T> : public Iterator<T>{}
template<typename T> class std::queue<T> : public Iterator<T>{}
template<typename T> class std::stack<T> : public Iterator<T>{}
// function signature
void sort(Iterator<T>, Iterator<T>);
sort(vec.begin(), vec.end());
各位可以思考看看, 哪一個才是可能的實現
在撰寫程式的過程中, 多思考看看的介面的意義:
- 使用者如何調用
- 模組之間的依賴關係
- 程式碼中的抽象與實現
再提出一個例子, 比方說今天我是 STEAM 上遊戲的開發人員, 我希望我的遊戲可以下載 Plugin
但是這麼多第三方人員, 要如何規範他們呢?
能不能提出一個基礎類別:
interface Plugin {
init()
load()
disable()
}
並規範所有 Plugin 的開發人員遵守呢?
RESTful
內容是參考以下網站, 並根據開發人員的經驗摘要, 可能會與網路上的一些資訊有出入
https://www.restapitutorial.com/、https://restcookbook.com/
筆者推薦的內容, 則是 Mircosoft 撰寫的雲端應用程式中的最佳做法
這裡先提一個懶人包: API 不等於 RESTful API, RESTful API 只是一種 API 風格而已, 不是規範
前言
再談論 RESTful API 之前, 先簡單說明一下現今的 Web App 所需的 API 會有幾個特色:
- 平台獨立
- 服務迭代
平台獨立的意思是, 不論 API 的內部如何實作, 都應該可以透過公開的、標準的協議進行存取
好比說有個註冊帳號 API, 對於客戶端來說, 不必在乎他是使用什麼程式語言開發的, 也不用知道使用什麼作業系統開發的
只要依照某種標準協議 Ex. HTTP, 就可以讓用戶端與Web服務進行資料交換
服務迭代的概念是, 客戶端與服務端是分開的
伺服器端的服務會不斷迭代更新並且新增功能, 而隨著服務端的更新, 客戶端應該要不進行修改, 依然可以順利運作
我認為的意義是這樣:舉例來說, 今日有個訂餐系統, 會上傳餐點的編號, 如 GHR201 之類的
而原先的程式設計如下:
async function order(foodId) {
const data = await fetch(apiEndpoint, {
headers: { 'Content-type': 'application/json' },
method: 'post',
body: JSON.stringify({ foodId });
}).then(res => res.json());
console.log( data ) /* 內容可能為
{
foodId: 'GHR201',
name: '肉絲炒飯',
price: 60
}
*/
dosomething(data) // 可能會客戶端的畫面顯示"下訂成功" 還有相關資訊
}
但是假設伺服端的回應修改了, 例如:
{
"uniqueId": "GHR201",
"foodName": "肉絲炒飯",
"orderTime": "14:19",
"expectTime": 1200
}
看起來多出了 "下訂的時間" 與 "預期送達時間", 像是 14:19 下訂, 20分鐘後左右會送到
但是 "name" 欄位被移除了, 修改為 "foodName", 這可能導致客戶端的程式無法順利運作
對於伺服端來說, 盡可能使得客戶端的輸入/輸出不需要額外的變動, 就是服務迭代的概念
SOAP(早期的API實現)
上個章節大概理清了:伺服器與客戶端需要有資料交換的機制, 且最好是與實作隔離
僅依賴在某種協定之上, 因此早期衍生出了 SOAP(Simple Object Access Protocol)
透過把 SOAP 繫結到 HTTP, 同時利用了SOAP與HTTP的優點
在HTTP上傳送SOAP並不意味著SOAP會覆蓋現有的HTTP語意, 而是HTTP上的SOAP語意會自然地對映到HTTP語意
在使用HTTP作為協定繫結的場合中, RPC請求對映到HTTP請求上, 而RPC應答對映到HTTP應答。然而, 在RPC上使用SOAP並不僅限於HTTP協定繫結
由 SOAP 發出的請求內容可能會是:
<soapenv:Envelope
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<soapenv:Body>
<req:echo xmlns:req="http://localhost:8080/wxyc/login.do">
<req:category>classifieds</req:category>
</req:echo>
</soapenv:Body>
</soapenv:Envelope>
而收到的回應可能會是:
<soapenv:Envelope
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:wsa="http://schemas.xmlsoap.org/ws/2004/08/addressing">
<soapenv:Header>
<wsa:ReplyTo>
<wsa:Address>http://schemas.xmlsoap.org/ws/2004/08/addressing/role/anonymous</wsa:Address>
</wsa:ReplyTo>
<wsa:From>
<wsa:Address>http://localhost:8080/axis2/services/MyService</wsa:Address>
</wsa:From>
<wsa:MessageID>ECE5B3F187F29D28BC11433905662036</wsa:MessageID>
</soapenv:Header>
<soapenv:Body>
<req:echo xmlns:req="http://localhost:8080/axis2/services/MyService/">
<req:category>classifieds</req:category>
</req:echo>
</soapenv:Body>
</soapenv:Envelope>
REST
在 2000 年時, Roy Fielding 提出了以具象狀態傳輸(REST)的架構來設計 Web 服務
REST 全稱 REpresentational State Transfer, 是一種設計風格, 請注意, 是設計風格
而不是標準或是協議, 相較 SOAP, REST 有幾個重要的特徵:
- Uniform Interface
- Stateless
- Cacheable
和 SOPA 或是 XML-RPC 相比之下, REST顯得相對簡單, 並且善用了 HTTP 的語意機制
除此之外, 也不局限於XML, JSON、YAML等格式, 都可作為資源的表達
重點在於 資源的表達
- 透過 URI 來指定存取的資源
- 針對資源, 常需要進行CRUD(Create, Read, Update, Delete), 剛好可對應到 HTTP Method
- 通過資源的表現形式來操作資源
大部分的實例, 都會通過 HTTP 設計 REST 風格的 API, 大致原則如下:
REST API 是依照資源來設計
架設今天有查詢餐廳訂單的API, 可能會是以下形式:
http://example.com/orders
並且可以透過「識別碼」, 存取特定的資源
http://example.com/orders/1
並且會透過交換資源的表示法, 與服務進行互動
{
"orderID":3,
"productID":2,
"quantity":4,
"orderValue":16.60
}
而統一的介面, 通常指的就是 HTTP 協議, 並透過常見的 HTTP Method 來分割 API 如 GET、POST、PUT、PATCH、DELETE 等方法
而 REST API 盡可能要求無狀態, 所有的HTTP要求應該是獨立的, 並且可能會以任何順序發生
這裡不好說明"無狀態的"HTTP是什麼意思, 因此反過來舉例包含狀態的HTTP: 像是常見的購物車系統, 今天在某個電商網站加入物品至購物車中, 關閉網頁後, 下次訪問還是知道購物車的內容; 或是某個網站, 如果以前登入過了, 就直接導向到會員頁面, 反之則是導向登入介面 以上兩個例子, 都是包含狀態性的HTTP請求
接下來, 直接看可能實作的 REST API 實例:
比方說電子商務系統中, 客戶與訂單的關係
可以透過包含訂單資訊的 POST API 建立訂單, HTTP 回應成功與否
https://adventure-works.com/orders // Good
https://adventure-works.com/create-order // Avoid
前面有提到, REST 傾向於使用 HTTP Method 描述行為, 因此 URI 不應包含動詞(create-order), 應該僅包含資源
要注意的事情是, REST 不是單純反映資料庫內部結構的API, 最終目的在於把實體與資源模型化
當然有很多REST的最佳做法, 但是暫且不提, 最後總結一下常用的方法與例子
| URI | POST | GET | PUT | DELETE |
|---|---|---|---|---|
| /customers | 建立新客戶 | 取得所有客戶 | 大量更新客戶 | 刪除所有用戶 |
| /customers/{id} | - | 擷取 {id} 的客戶資料 | 更新 {id} 的客戶資料 | 刪除 {id} 的客戶資料 |
| /customers/{id}/order | 為客戶 {id} 建立訂單 | 擷取 {id} 客戶的所有訂單 | 更新 {id} 的客戶訂單 | 刪除 {id} 的客戶訂單 |
這只是其中幾個例子, 這裡建議可以看看 MOTC API的真實案例